
A lot of teams start fraud work only after the first painful pattern shows up. Orders look fine until chargebacks climb. New signups look healthy until support notices waves of fake accounts. A referral program performs well until someone automates it into a money drain.
That's usually the moment leaders realize fraud isn't a side problem. It sits inside growth, payments, trust, and operations all at once.
The hard part is that modern fraud detection systems aren't just a single model or a blacklist. They're a mix of streaming data, rules, machine learning, review workflows, and constant tuning. If you also use AI features inside your product, the operational burden gets bigger because you now need to manage prompts, parameters, logs, and spend with the same discipline you apply to fraud controls.
Why Your App Needs an Immune System
A healthy growth curve can hide a fraud problem for weeks.
A retail app rolls out a faster checkout. Conversion goes up. Marketing spends more because the numbers look good. Then finance starts seeing chargebacks, support gets flooded by locked-account complaints, and the promo budget is drained by abuse that looked like normal customer activity at first. By the time the pattern is obvious, the business is already paying for it in revenue, team time, and customer trust.
Fraud detection gives your application an early warning and response layer. It watches for suspicious behavior before losses stack up, then routes each case to the right action: allow, block, step up verification, or send to review.
Manual review usually lasts longer in planning than it does in production.
At low volume, a team can inspect orders, check account history, and make reasonable calls. Once transaction count rises, or fraud shifts from obvious theft to blended behavior that looks partly legitimate, that approach gets expensive fast. Analysts become the bottleneck. Good customers wait. Bad actors test your flows faster than your team can respond.
The cost problem is only part of it. Speed matters too. A fraud control that catches abuse three days later may help reporting, but it does not stop payout fraud, account takeover, referral abuse, or promo loss in time to matter. For a lot of apps, a key requirement is not just detection. It is decisioning at the moment risk appears.
Fraud is an application design problem
Teams often assign fraud to payments or compliance. In practice, it shows up across the product. Onboarding can invite fake accounts. Login and password reset flows can open the door to account takeover. Wallet credits, refunds, loyalty programs, referral mechanics, and support tooling can all become abuse paths if nobody designed them with misuse in mind.
That is why fraud work should sit alongside broader application security best practices, product design, and operations planning, not just gateway settings.
The practical goals are straightforward:
- Protect revenue: Reduce theft, chargebacks, promo abuse, and payout loss.
- Protect good users: Keep friction low for legitimate customers.
- Protect operations: Reserve human review for ambiguous cases, not every alert.
- Protect future automation: If the app uses AI for support, verification, or internal workflows, those decision paths need controls and auditability too.
The project succeeds or fails in operations
Many first fraud projects focus on picking a model or vendor. That is rarely the hard part.
The harder part is running the system once real traffic hits it. Rules change. Fraud patterns shift. Thresholds drift. Analysts need review queues that make sense. Product teams need to know how much friction the business will accept. Leadership needs clear answers on false positives, missed fraud, and review cost. If those operating decisions are vague, the system turns into scattered rules, dashboard alerts, and exceptions nobody trusts.
A good fraud program is not just accurate. It is manageable. Your team should be able to explain why a user was challenged, who changed the rule, what happened after the decision, and how the control affected approval rate, losses, and support volume.
That is the standard to design for on day one.
Anatomy of a Modern Fraud Detection System
The easiest way to understand fraud detection systems is to think about an airport security checkpoint. People arrive from different places. Staff collect information, screen for risks, route obvious cases quickly, and send uncertain cases for deeper inspection.
Your app does the same thing with transactions, logins, account changes, and payouts.
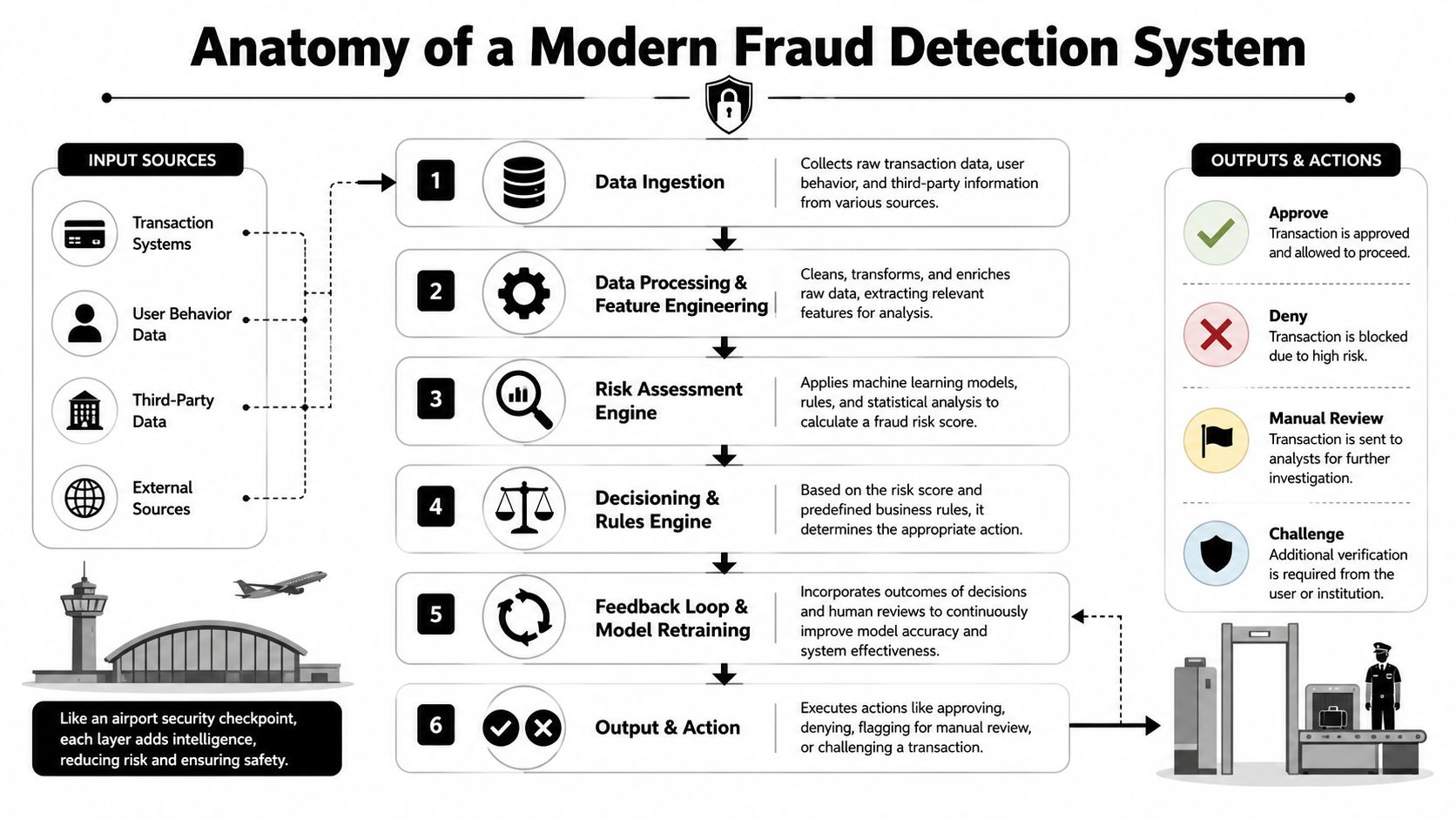
Data ingestion
Everything starts with input. If the system doesn't see the right events, nothing downstream matters.
Typical inputs include transaction details, login attempts, device information, session behavior, geolocation, account history, and third-party signals. The key mistake here is over-collecting random data while under-instrumenting the moments that matter. You need event coverage tied to actual fraud decisions, not a giant pile of telemetry with no clear use.
A good ingestion layer answers practical questions:
- What happened: Login, purchase, payout request, password reset, address change.
- Who did it: Account, session, device, payment instrument, support agent.
- What context matters: Velocity, prior behavior, mismatch signals, linked entities.
- What action followed: Approved, declined, challenged, reviewed, refunded.
Data processing and feature engineering
Raw events usually aren't useful on their own. Teams need to turn them into features the system can score.
That means cleaning noisy records, normalizing formats, enriching events with history, and generating useful indicators such as unusual device switches, rapid retries, or inconsistent account behavior. In practice, whether projects become effective or confusing often depends on these processes.
Practical rule: Build features that explain risk in business language. “New device plus changed shipping behavior” is more actionable than a generic anomaly score by itself.
If analysts and product managers can't understand the inputs, they'll struggle to tune the outputs.
Risk assessment and decisioning
This is the checkpoint moment. The system applies rules, statistical methods, or machine learning to produce a risk score or recommendation.
For high-risk products, the scoring layer usually isn't one model. It's a stack. A rules engine may catch known abuse patterns. An anomaly detector may spot outliers. A graph layer may reveal linked accounts. A behavior model may distinguish a real customer from automation or takeover activity.
The decisioning engine then converts that intelligence into action:
| Decision type | What it means | Common business use |
|---|---|---|
| Approve | Risk looks acceptable | Keep checkout or login fast |
| Deny | Risk is clearly too high | Block obvious abuse |
| Challenge | More proof is needed | Trigger MFA or step-up verification |
| Review | A human should inspect | Handle ambiguous or high-value cases |
Case management and feedback loops
A fraud system without review tooling is incomplete.
Analysts need a queue, evidence, reason codes, linked history, and a place to record outcomes. Those outcomes are what improve the system later. They tell you which alerts were useful, which policies were too aggressive, and which fraud patterns slipped through.
The feedback loop is what turns a static detection setup into an operating capability. Without it, your fraud stack becomes a museum of old assumptions.
Choosing Your Weapon Fraud Detection Approaches
Not every detection method fits every business. The right choice depends on your transaction volume, fraud type, review capacity, and appetite for complexity.
Some teams start with rules because they want control. Others jump to machine learning too early and end up with a model nobody trusts. Most mature programs land on a hybrid approach because it matches how fraud operates.
Comparison of Fraud Detection Approaches
| Approach | How It Works | Best For | Pros | Cons |
|---|---|---|---|---|
| Rule-based systems | Uses fixed policies such as velocity checks, mismatches, blocklists, and thresholds | Early-stage products, known attack patterns, compliance-driven controls | Fast to deploy, easy to explain, deterministic | Rigid, high maintenance, easy for attackers to learn around |
| Machine learning | Learns patterns from historical behavior or identifies unusual activity without explicit labels | Higher-volume environments, changing attack patterns, richer datasets | Better at nuance, stronger against evolving behavior, can reduce reliance on static thresholds | Needs data quality, model monitoring, tuning, and operational trust |
| Hybrid systems | Combines rules, ML scoring, and human review | Most scaling ecommerce, fintech, and multi-channel apps | Balances speed, control, and adaptability | More moving parts, more integration work, more governance required |
Rule-based systems still matter
Rules get dismissed too quickly. They're useful when the pattern is clear and the business wants predictable action.
Examples include blocking impossible combinations, rate-limiting obvious abuse, or forcing review when a payout request hits a known risk condition. Rules are also easier to audit than a black-box score.
But rule stacks have a ceiling. Every new fraud pattern turns into another exception. Over time the system becomes brittle. Teams end up managing a tangle of if-then logic that slows product changes and still misses new attacks.
Machine learning handles nuance better
Machine learning becomes valuable when static conditions stop being enough. Instead of asking, “Did this event break a rule?” the model asks, “Does this behavior look like the kind of event that usually turns into fraud?”
That matters most when user behavior is messy. Real customers travel, buy gifts, change devices, and make odd purchases. Fraudsters also create those patterns on purpose. A good model can separate “unusual but legitimate” from “unusual and risky” better than a threshold can.
If your team needs a clean primer on model families, this guide on supervised and unsupervised machine learning is a useful companion when deciding what kind of scoring logic to support.
One notable area is behavioral biometrics. Advanced systems using behavioral biometrics and deep learning can achieve true positive rates exceeding 90% by analyzing signals such as keystroke dynamics and mouse movement, according to Fraud.com on advanced fraud detection. That doesn't mean every business needs deep learning on day one. It does mean richer user interaction data can materially improve detection quality.
Hybrid usually wins in production
The most practical design for first major implementations is hybrid.
Use rules for hard guardrails. Use machine learning for pattern recognition. Use human review for edge cases and high-value events. This lets your team keep control where certainty matters while letting the system adapt where fraud changes fastest.
That's especially relevant outside classic card fraud. If you work in dealership software, fleet finance, or adjacent marketplaces, the playbook for preventing car fraud in motor trade is a good reminder that document issues, identity concerns, and transaction abuse often overlap. The detection method has to match the abuse surface.
Pick the simplest approach that still lets you adapt. Complexity you can't operate is worse than modest detection you can tune every week.
Architecting for Real-Time Fraud Prevention
In fraud, slow often means useless.
If a payment decision arrives after checkout is complete, or an account takeover alert appears after funds move, the system didn't prevent much. It only documented the loss. That's why architecture matters as much as detection logic.
For financial and ecommerce applications, authorization decisions often need to happen in under 100 milliseconds, with lighter scoring in 10 to 50 milliseconds and deeper analysis in 100 to 500 milliseconds before manual review, according to OpenMetal's guide to big data for fraud detection. The same source cites a 10.60% suspected fraud attempt rate, described as a 183% rise.
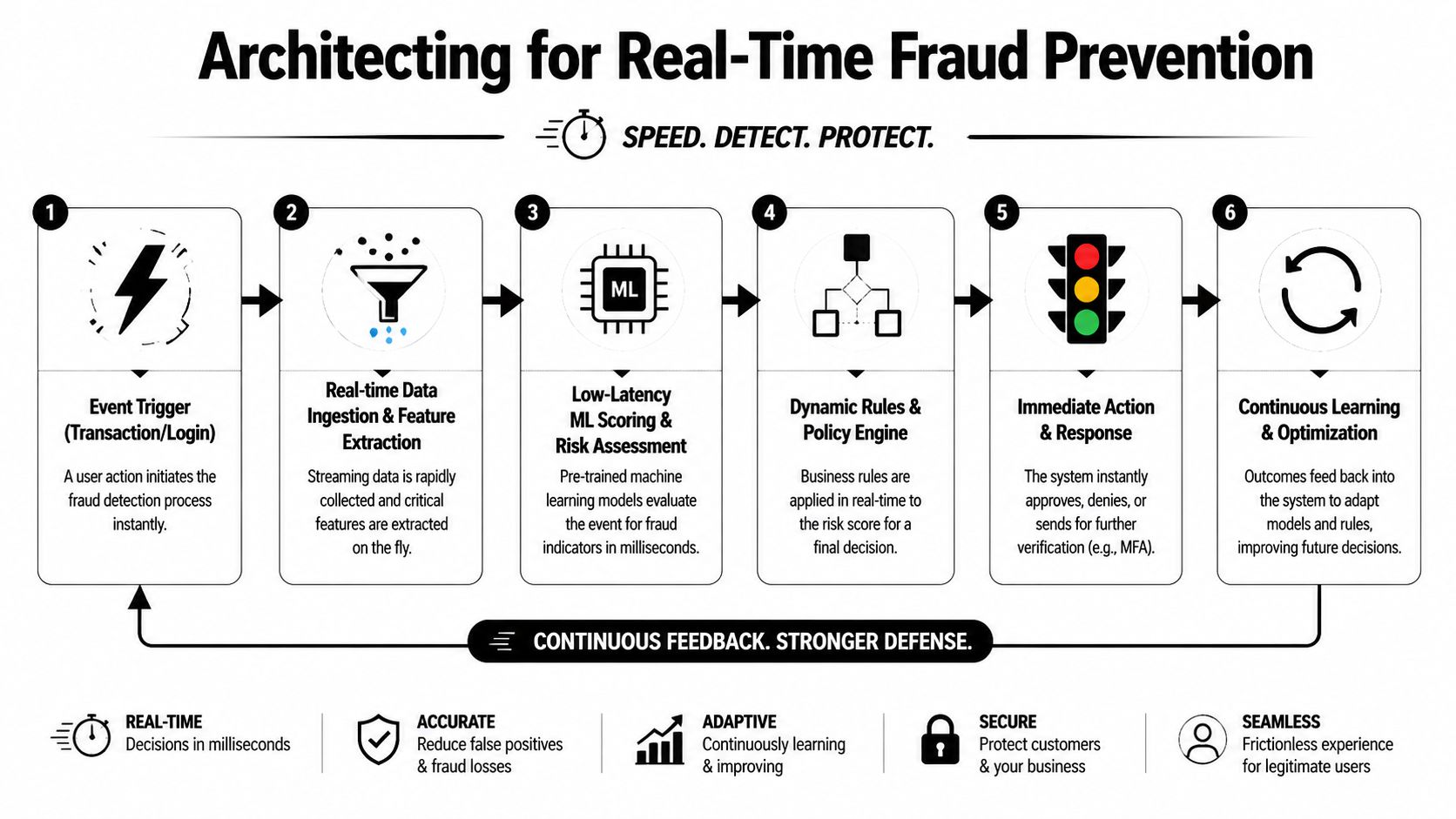
What the real-time path actually looks like
A useful mental model is a relay race. Each handoff has to be fast, predictable, and instrumented.
Event fires
A login, transaction, password reset, or payout request hits your system.Streaming pipeline captures it
Infrastructure such as Kafka, Pub/Sub, or comparable event plumbing moves the event immediately instead of waiting for a batch job.Features are assembled
The system enriches the event with account history, device context, prior actions, and business metadata.Scoring happens
Rules and models evaluate risk.Decision engine acts
Approve, deny, challenge, or route to review.Outcome gets logged
The event, score, rationale, and result go back into analytics and future tuning.
Low latency needs disciplined architecture
Teams often assume real-time means “we'll just call the model API during checkout.” That's not enough.
You need a path designed for low-latency reads, predictable dependencies, fallback behavior, and observability. If feature retrieval is slow, the model won't save you. If your scoring service depends on fragile synchronous calls, you'll create checkout delays or silent failures.
A strong architecture usually includes:
- Streaming ingestion: Events move as they occur, not on a reporting schedule.
- Online feature access: The scoring layer can fetch recent user and account state quickly.
- Tiered decisioning: Fast checks happen inline. Deeper review logic can happen off the critical path.
- Graceful degradation: If one enrichment service fails, the system still makes a safe decision.
- Operational visibility: Engineers and fraud ops can see latency, queue growth, failed calls, and model outputs.
If your leadership team is still aligning around streaming architecture more broadly, this primer on applying data pipelines to business intelligence helps connect the fraud use case to the larger data platform decisions you're already making.
Seconds beat minutes
The practical business question isn't whether streaming is elegant. It's whether your business can afford delay.
A fraud system that spots abuse within seconds can shut down repeat attempts, freeze suspicious sessions, and trigger step-up verification before more damage happens. A delayed system often forces your staff into cleanup mode.
If your fraud alerts live in dashboards but not in the user flow, you built reporting, not prevention.
The Hidden Work Training Monitoring and Compliance
A lot of first-time fraud projects assume the hard part is launching. It isn't. The hard part is keeping the system useful after launch.
Fraud patterns change. Customer behavior changes. Product flows change. Marketing campaigns create new edge cases. Payment mix changes. Support teams add manual workarounds. All of that affects model performance.
The set-it-and-forget-it model fails fast
Real systems deal with data scarcity, label delay, and concept drift, and effective operations depend less on one perfect model and more on strong feedback loops, investigation capacity, and data quality, according to Fraud.com on anomaly detection.
That point gets missed constantly. Teams obsess over model selection, then underinvest in case labeling, review workflows, and data hygiene. When confirmed fraud labels arrive late, the model learns slowly. When product teams change flows without updating events, the system starts scoring incomplete context. When analysts don't feed outcomes back, thresholds freeze in time.
What to monitor every week
You don't need exotic governance to start. You need disciplined operating habits.
- Decision quality: Review which approvals later proved risky and which declines blocked legitimate users.
- Queue health: Watch whether manual review is filling with low-value alerts.
- Rule and model drift: Compare current behavior with what the system was tuned against.
- Data integrity: Check for missing events, broken schemas, or stale enrichments.
- Policy side effects: Spot product friction caused by aggressive controls.
A practical review meeting should include fraud ops, engineering, product, and support. Each team sees a different failure mode. Product sees friction. Ops sees patterns. Engineering sees missing data. Support hears the customer pain first.
Strong fraud programs don't just detect abuse. They learn from every disputed outcome, every override, and every false alarm.
Compliance changes your design choices
Compliance isn't a legal footnote. It changes architecture, retention, explainability, and workflow design.
If you operate in regulated environments or handle sensitive identity signals, you need to think about data minimization, access controls, review traceability, and user challenge flows early. The model may be accurate, but if your team can't explain why a customer was blocked or how data was used, you've created operational risk.
For teams that are aligning fraud controls with identity verification and onboarding requirements, this overview of Homebase insights on KYC tools is helpful context. KYC, fraud screening, and case management often intersect in the same operating pipeline even when different teams own them.
Human review is part of the system
Many leaders treat manual review as a temporary patch. In reality, it's part of the design.
The mistake is dumping too many weak alerts onto investigators. Good fraud operations reserve human attention for expensive ambiguity. That means your models, rules, and product flows should aim to shrink the gray area, not just generate more tickets.
Your Implementation Plan Build Buy or Hybrid
A team usually reaches this point after the first painful lesson. Chargebacks are rising, support is handling angry customers, and engineering has a queue of one-off checks that no longer scale. The question is no longer whether fraud needs attention. The question is which path gets a usable system into production without creating a second operational mess.
That is the build vs. buy decision. It is less about technical preference and more about time, control, staffing, and how specific your fraud patterns are to your product.
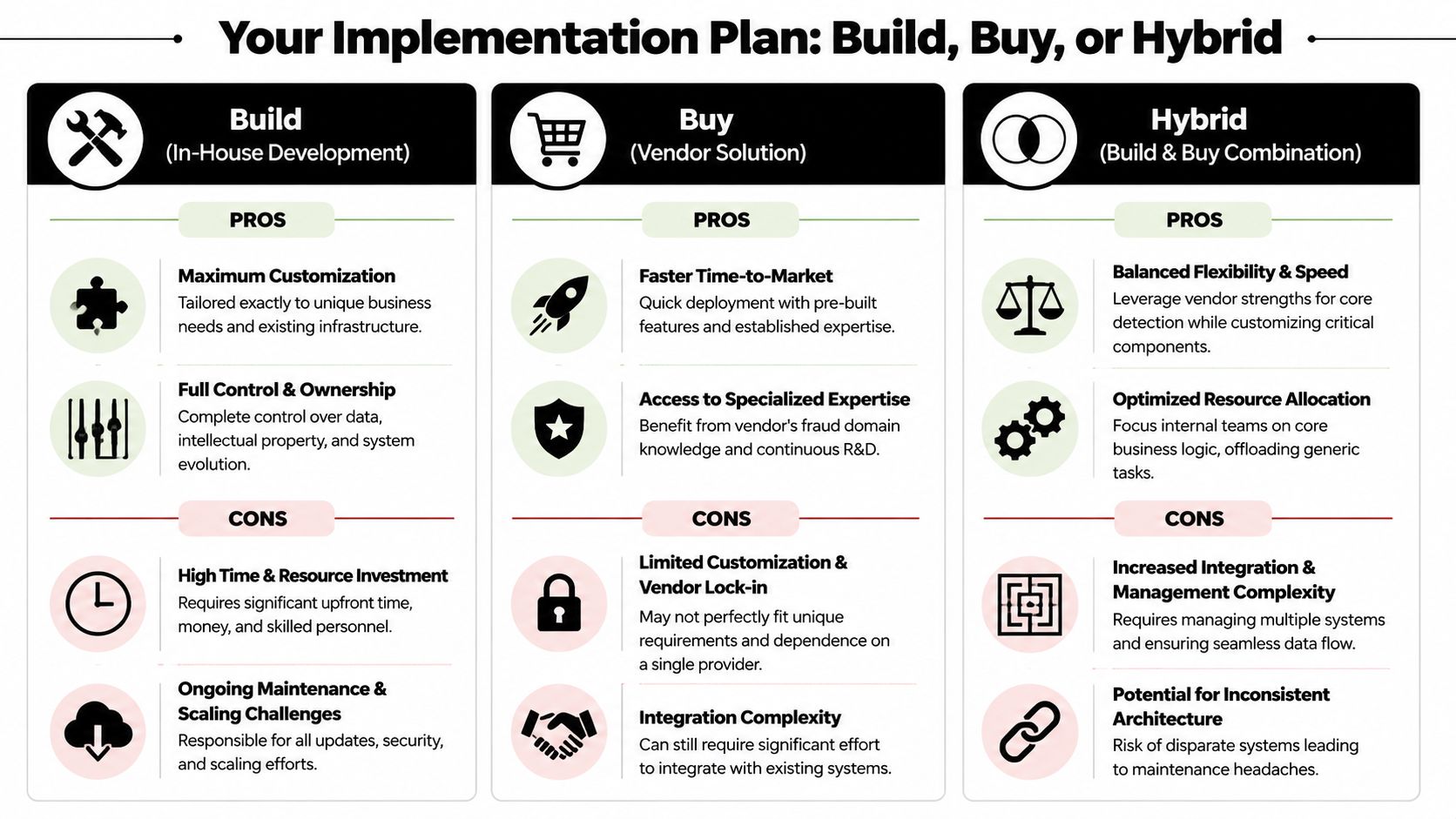
When building makes sense
Build when fraud logic is tightly connected to your unit economics, user flows, and proprietary signals.
That is common in marketplaces, embedded finance products, healthcare billing, gaming economies, and loyalty programs with unusual abuse patterns. In those cases, an outside model may score risk correctly in the abstract but still miss the behavior that directly costs you money. A custom system lets your team define events, tune thresholds around margins, and connect decisions to the parts of the workflow that matter most.
The trade-off is ownership. Building means taking responsibility for event instrumentation, feature pipelines, rules, model operations, analyst tools, monitoring, retraining, and audit history. If the team cannot support that work for the next 12 to 24 months, a pure build approach usually looks better in planning than it does in production.
When buying makes sense
Buy when speed matters, your fraud patterns are relatively common, and the business needs coverage before it needs differentiation.
A vendor can give you risk scoring, case management, device intelligence, and shared network signals much faster than an internal team can assemble them. That can reduce exposure quickly, which matters if fraud losses are already visible in finance reports or investor questions. It also lowers the staffing burden early on, especially for companies that do not yet have dedicated fraud engineers or analysts.
You give up some control in return.
Vendor workflows can be rigid. Data models may not match your product. Explainability may be limited when an operations lead asks why a good customer was blocked. Those limits are manageable if your goal is fast baseline protection. They become expensive if fraud policy is a core part of your customer experience or margin model.
Why hybrid is often the best first move
For a first major fraud project, hybrid is often the safest decision.
Use a vendor for baseline detection and supporting infrastructure. Keep product-specific rules, exception handling, review queues, and decision policy in your own stack. That gives the business faster deployment without forcing you to accept every vendor assumption about risk, workflow, or customer treatment.
This approach also creates a cleaner migration path. If the vendor performs well, you keep using it for broad coverage. If gaps show up later, your internal signals and policy layer already exist, so you can replace parts of the system without starting over.
A practical decision filter:
- Choose build if fraud prevention is part of your competitive advantage and your team can own the full operating model.
- Choose buy if you need coverage quickly and standard controls address most of your current exposure.
- Choose hybrid if you want fast deployment, but you also need policy control in the parts of the product that are unique to your business.
Don't ignore the control plane
Teams often budget for models and rules but miss the operational layer around them.
If investigators use AI-assisted review, if analysts rely on internal copilots, or if policy decisions depend on prompt-driven tools, those systems need version control, logging, parameter management, and cost tracking. In a hybrid setup, that work becomes part of fraud governance because decision quality now depends on both detection logic and the tools people use to review edge cases. Wonderment Apps offers a prompt management system for that operational layer, including prompt versioning, parameter controls for internal database access, logging across integrated AI systems, and cost visibility.
A good implementation plan does not chase perfect automation. It sets up a system your team can ship, explain, measure, and improve without rebuilding the entire stack every six months.
If you're planning a fraud detection project inside a web or mobile product, Wonderment Apps can help you scope the right path, whether that means custom architecture, AI modernization, better internal tooling, or a hybrid rollout that fits your existing stack. A practical next step is a demo and technical conversation focused on your workflows, risk surface, and the operational controls your team will need.