
Data Pipeline is a set of data processing units which transforms raw data from a variety of data sources into a meaningful format for data analytics, fast data serving layers, data warehouse, business intelligence (BI) and real-time querying of data.
The importance of data pipeline and business intelligence has grown exponentially over the past few years and the followings are the main reasons:
- There are so many data sources at any organization and business owners want to make sense of their data by connecting all of their data sources.
- The amount of data being produced is exponentially bigger than few years ago and it has become a lot more challenging for businesses to analyze their data using traditional systems and softwares.
- Business owners have become a lot more sophisticated when it comes to analyzing their data and building very sophisticated business intelligence tools and dashboards.
- It’s pretty vital for any online business to constantly improve their sales funnels in order to be able to survive in any online market.
- The volume of data being produced nowadays is so high that the speed of data delivery to end users has become very challenging.

Why do I need to build a data pipeline?
Data pipelines are all over the place on web and mobile applications and there’s a very good chance that you are an end-user of these pipelines on a daily basis without even noticing them. Here are some examples of the data pipeline applications that you probably have engaged with in the past:
- Recommendation Engines: Every single e-commerce application tries to increase their AOV (average order value) by showing a set of recommended products throughout their checkout funnel. These logic behind these recommendation engines can get pretty complex and a team of data scientists are constantly designing and tweaking very sophisticated algorithms in order to show a few recommended products to an end-user. Here are some examples:
- Yelp – Other great restaurants nearby
- Amazon – Your recently viewed items and featured recommendations
- Facebook and Linkedin – People you may know
- Ad Networks: There are so many parameters that come to play when an Ad Network wants to make a decision about which Ad to display to the user. Some of these parameters might be impression data, click data, user demographic data, and etc…. The combination of these data points are constantly being analyzed in a data pipeline in order for an Ad unit to be shown to you on a page where you are reading an article or shopping for an item.
- Search Algorithms: Most of the search algorithms on major websites are pretty smart these days and they take a lot of user data in order to show you the most relevant result possible. All of these algorithms are constantly going under machine learning algorithm in a data pipeline in order to show results under a few hundred milliseconds to the end-user.

What type of data sources are feeding into my data pipeline?
There are so many data sources available now for any online business and businesses want to make sense of their data by creating a relationship between these sources and telling a story about their users or dividing them into different user cohorts. For example, an online e-commerce company might want to bring their data together from the following data sources in order to make sense of their data:
- Web analytics tool such as Google Analytics
- User event tracking system such as Mixpanel
- Search engine marketing tool such as Google Adwords
- A/B testing platform data such as Optimizely or Visual Website Optimizer
- User data
- Product catalog data and their attributes
- Revenue and sales data
- Sales funnels and checkout flows
- Fraudulent transaction data
- And etc…
How complex are these data pipelines to build?
The complexity of a data pipelines comes down to the following elements:
- The amount of data that is being ingested by the data pipeline – A data pipeline that ingests hundreds of millions of events per second is a lot more challenging to build compared to a data pipeline that only ingests a few hundred events per second. Netflix ingests over 700 billions of messages on an average day and they are currently operating on 36 Kafka clusters.
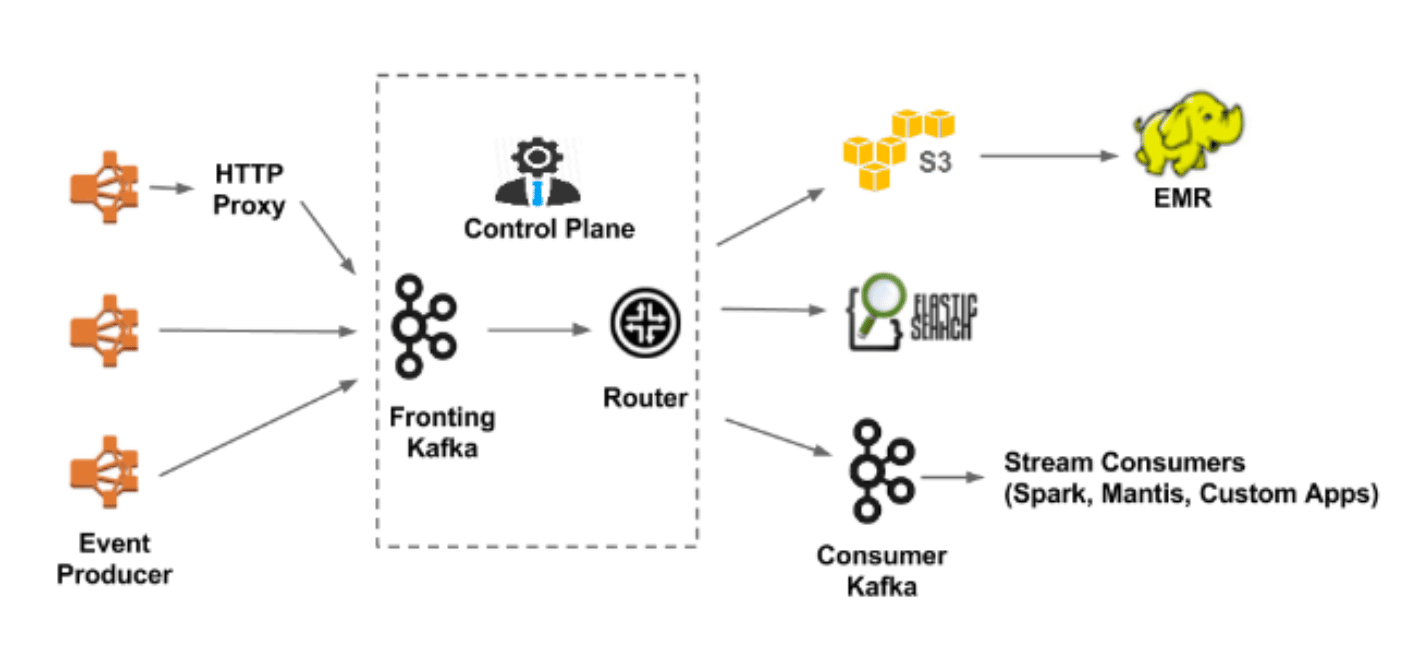
- The goals of the data pipeline – There are many different possibilities after you have a data pipeline implemented for your business and this data pipeline can be utilized for different goals and purposes. Here are some of the most common use cases and each can have its own level of complexity:
- Advanced Search Systems – The result of the processed data can be stored in Elasticsearch so that this data is highly available and searchable for other applications in an organization. Elasticsearch can also be utilized as the speed layer in order to access complex and large volume of data in a fraction of second.
- Data Analytic Tools and Data Visualizations Dashboards – Batch processing can be performed in the data pipeline so that complex business intelligence queries are performed on the combination of data in order to generate analytical dashboards. One of the most powerful platforms that can enable batch processing on your data is Apache Spark which can directly be connected to your data pipeline.
- Real-Time Queries – Business intelligence team will be able to perform real-time queries on data and make decisions on the fly. This task is fairly complicated for companies who deal with big volume of data and Spark SQL is a great tool that can let BI team perform real-time on large set of data.
- Data Warehouses – The result of the processed data can be stored in data warehouses in order for the BI team to perform queries on their historical data. Your data pipeline can directly feed data into a data warehouse such as Amazon Redshift.
- Data Science and Machine Learning – The result of the processed data can be connected to Spark MLlib (Machine Learning Library). Spark MLlib is a scalable machine learning library of common learning algorithms and utilities, including classification, regression, clustering, and etc….
What are the main elements of a data pipeline and what are the major technology leaders for every element?
Data pipelines are consistent of the following main elements:
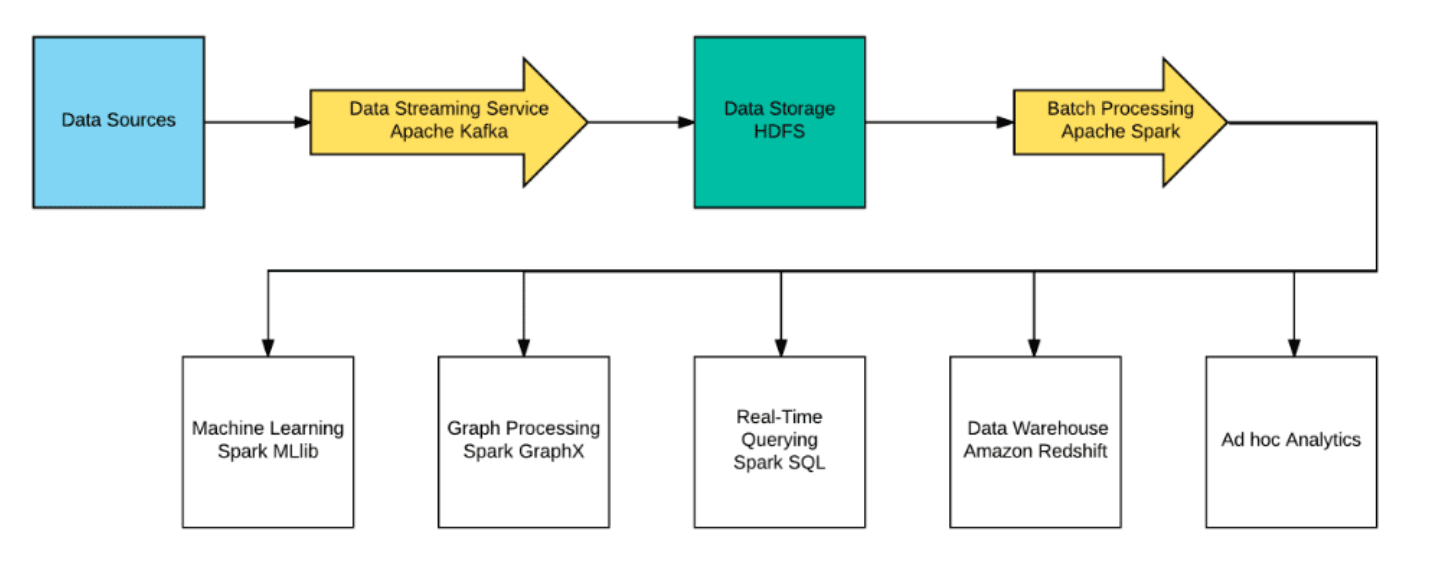
- Data Ingestion Unit – This data ingestion unit is responsible for collecting data from all the different data sources that are contributing to your data pipeline. Your organization will have a collection of different data sources and each data source might need a different connector in order to bring this data over.
- Modern Data Sources: You might be able to migrate your more modern data sources by integrating with their APIs and write jobs that will bring new data over on a regular basis.
- Data Dumps: Some of your older data sources might not have APIs and you will probably have to write custom jobs in order to dump them into your data source.
- CSV: Some data sources support CSV exports and you will have to write an importer that ingests the CSV data on a regular basis.
- Custom APIs: You might want to write custom APIs in order for your applications to send real-time data into your data pipeline.
- Message Bus and Data Streaming System- You need to have a data streaming platform where you can process high-throughput data with low latency in real-time. This system needs to be massively scalable so that you can stream all of your data in a unified system. Apache Kafka is a very common distributed streaming platform which lets you publish and subscribe to streams of data like a messaging system, store streams of data in a distributed and replicated cluster, and process streams of data in real-time.
- Large Scale Data Storage System – You need to be able to store your data in a persistent data storage system where you can keep all of your historical data. HDFS is the most common big data file system that provides scalable and reliable data storage.
- Batch Data Processing System – You need a big data processing framework in order to run batch processing on your data. Apache Spark is one of the most powerful data processing engines out there which can process your data at a massive scale at a speed up to 100x faster than Hadoop. Spark has easy-to-use APIs for operations on large datasets. Spark is a unified engine that has support for SQL queries, data streaming, machine learning and graph processing.