
Your AI roadmap probably looks good on a slide.
You want better product recommendations, faster reporting, smarter support workflows, cleaner forecasting, and maybe a layer of generative AI on top of it all. Then practical challenges emerge. Reports arrive late. Data sits in too many systems. Teams wait for overnight jobs. Customer-facing experiences feel one step behind.
That gap is where many modernization efforts stall. The AI idea is strong, but the data foundation can't keep up.
For business leaders, spark and hadoop matter not because they’re trendy infrastructure names, but because they solve a very practical problem. They help teams store huge amounts of data, process it at scale, and move from slow batch operations toward systems that can support analytics, machine learning, and responsive applications.
The catch is that fixing data speed creates a second challenge. Once your applications can feed AI in near real time, you also need a clean way to manage prompts, parameters, logs, and model spend across those workflows. That operational layer becomes just as important as the data layer.
The Data Bottleneck Holding Back Your AI Ambitions
A retail team wants to personalize product recommendations during a shopping session. A fintech team wants to flag risky behavior as transactions move through the platform. A healthcare platform wants cleaner operational insight without waiting on stale exports.
All three teams run into the same problem. Their applications generate data faster than their legacy stack can organize and process it.
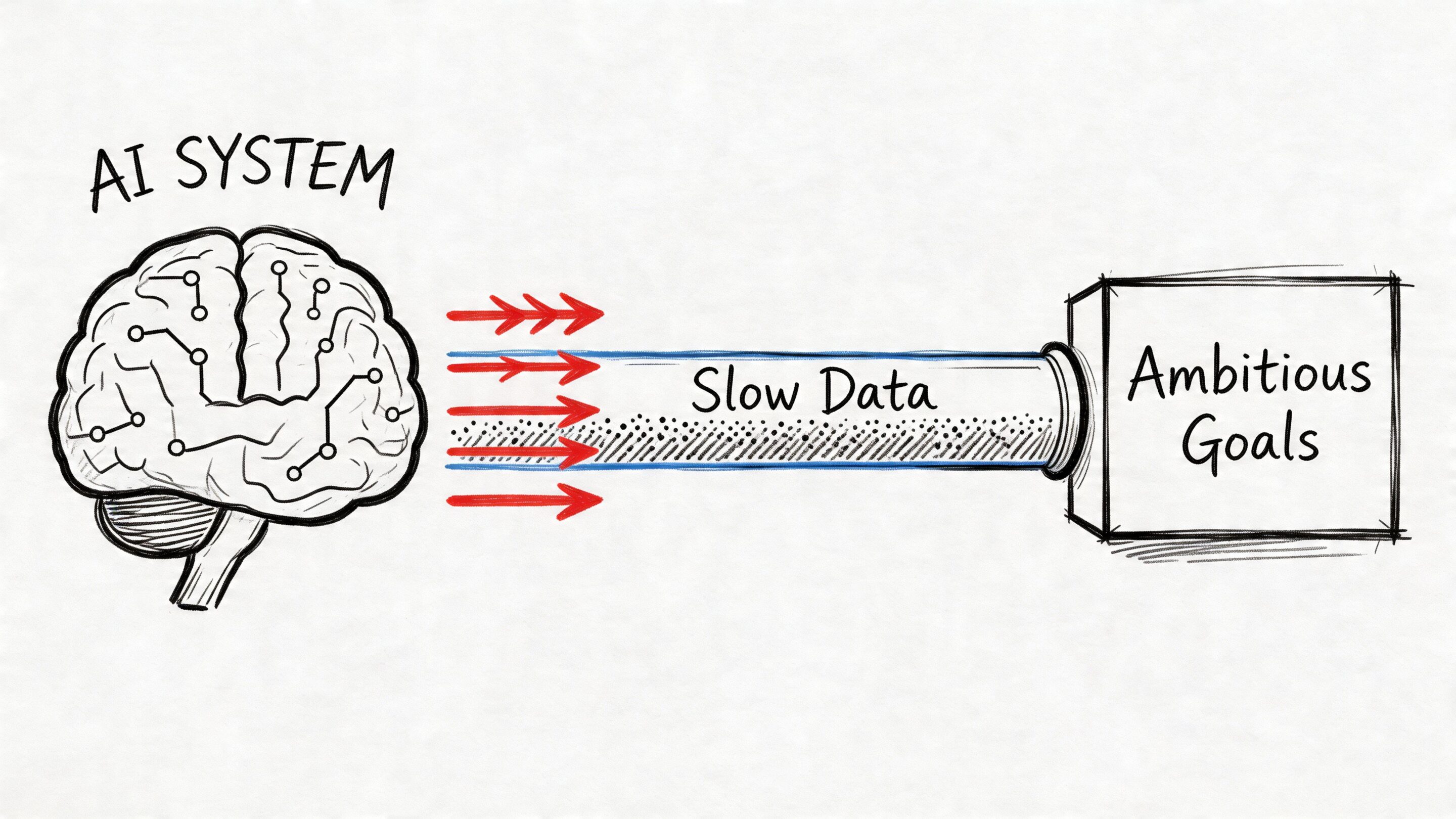
If that sounds familiar, the issue usually isn’t the AI model. It’s the pipe feeding the model. Data arrives late, arrives in the wrong shape, or gets trapped in systems designed for reporting windows instead of live decision-making. That’s why modern teams often revisit their pipeline architecture before they expand AI features. A practical primer on that foundation lives in Wonderment’s guide to applying data pipelines to business intelligence.
What the bottleneck looks like in business terms
Leaders usually notice symptoms before they hear any platform names:
- Slow decisions: Analysts wait for large jobs to finish before they can answer simple operational questions.
- Weaker customer experiences: A recommendation or alert that arrives late might as well not exist.
- Rising engineering drag: Teams spend time moving data around instead of building features.
- Limited AI ambition: You can’t ask an application to reason over fresh data if the data arrives on yesterday’s schedule.
Hadoop and Spark rose to prominence. Hadoop became the backbone for handling massive datasets across clusters of commodity hardware. Spark later changed expectations by making many workloads dramatically faster through in-memory processing.
Practical rule: If your AI initiative depends on fresh, usable data, your first modernization project probably isn’t the model. It’s the data engine underneath it.
Why this matters before you buy more AI tooling
AI applications don’t run on hope. They run on retrieval, transformation, scoring, logging, and repeatable execution. If those pieces are slow or brittle, every new AI feature becomes expensive to maintain.
Business leaders often ask for “real-time AI” when what they really need is a data architecture that can support two different motions at once:
- Long-term, low-cost storage for very large datasets
- Fast processing for analytics, machine learning, and responsive app behavior
That’s the sweet spot where spark and hadoop become useful. One gives you a durable foundation. The other gives you speed where speed matters.
Meet the Big Data Titans Hadoop and Spark
A useful buying conversation starts with a simple distinction. Hadoop and Spark were built to solve different parts of the same enterprise data problem.
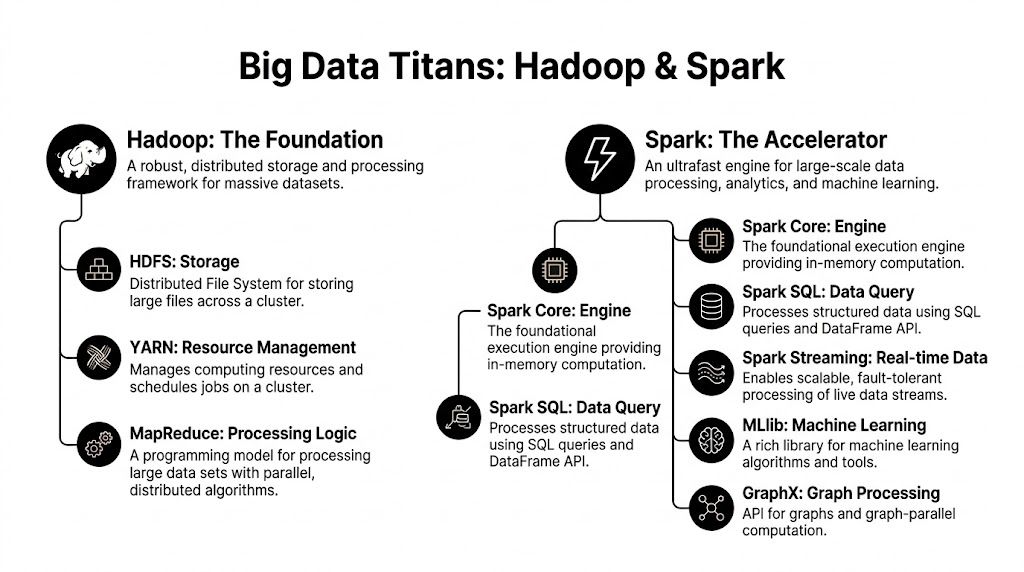
For a business leader, the easiest way to frame them is this. Hadoop gives you a durable, low-cost base for storing and organizing very large datasets across many machines. Spark gives you a faster way to process data when teams need answers quickly, retrain models often, or react to events while they are still relevant.
Hadoop is the foundation
Hadoop arrived first and changed the economics of big data. It made it practical to spread storage and compute across clusters of commodity servers instead of relying only on expensive specialized systems.
Its main pieces each do a specific job:
- HDFS: stores large files across many machines with fault tolerance
- YARN: allocates cluster resources and coordinates jobs
- MapReduce: runs large batch processing tasks in a step-by-step model
That design matters because it favors reliability, scale, and cost control. If your company needs to keep years of logs, transaction history, IoT data, or compliance records, Hadoop is well suited to that role. It is patient infrastructure. It handles huge volumes well, even if the work is not especially fast.
Spark is the accelerator
Spark came later with a different priority. It reduces the delay between a question and an answer.
Instead of writing intermediate results back to disk after every step, Spark often keeps working data in memory and uses a DAG execution engine to optimize how tasks run. In practice, that makes a major difference for workloads that revisit the same data again and again, such as interactive analytics, feature engineering, model training, and streaming pipelines. Integrate.io’s comparison of Spark and Hadoop MapReduce explains why this architecture often outperforms traditional MapReduce for those patterns.
Spark also brings a broader processing toolkit into one environment:
- Spark SQL for querying structured data
- Structured Streaming for near real-time pipelines
- MLlib for machine learning work
- GraphX for graph analysis
That combination is one reason Spark became popular with teams building modern applications and AI workflows. Faster iteration changes the business case. Analysts can test ideas sooner. Data science teams can retrain more often. Product teams can support features that depend on fresher data.
Where confusion usually starts
The common mistake is to compare Hadoop and Spark as if they are the same type of product.
They are not.
Hadoop is an ecosystem that includes storage, resource management, and a traditional batch processing model. Spark is primarily a compute engine designed for faster, more flexible processing across several data workloads.
A practical analogy helps here. Hadoop functions like the long-term industrial facility where raw material is stored, organized, and governed. Spark behaves more like the production line optimized for rapid turnaround on active jobs. Both matter, but they serve different operational goals.
Another source of confusion is the phrase "Spark is faster than Hadoop." That statement hides an important detail. Spark is usually being compared with Hadoop MapReduce, not with every part of the Hadoop ecosystem. Speed is only part of the story anyway. The larger difference is how each system approaches work. Hadoop emphasizes durable storage and methodical batch execution. Spark is built for iterative processing, repeated reads, and time-sensitive analysis.
The practical takeaway
If your priority is economical storage, long retention windows, and large scheduled batch jobs, Hadoop remains a sensible choice.
If your priority is interactive analytics, frequent model updates, streaming data, or AI applications that depend on fresher context, Spark is often the better fit.
For many enterprises, the fundamental decision is not which name wins. That decision is where each tool belongs in a modernization plan. That is the framing that supports cost-effective AI. Store data where storage is cheap and reliable. Process data where speed creates business value. Then add the workflow layer on top, including the prompt and orchestration systems that govern how AI applications use that data responsibly.
The Power Couple How Spark and Hadoop Work Together
A leadership team usually runs into trouble when this decision gets framed as one winner replacing the other. In practice, the stronger architecture often combines them.
The common enterprise pattern is simple. Hadoop provides the storage foundation and cluster management. Spark uses that foundation to process data quickly when the work calls for faster analysis, machine learning, or near-real-time response.
A practical setup often looks like this:
- Hadoop HDFS stores large volumes of data economically
- YARN allocates cluster resources across jobs
- Spark runs processing workloads against that shared data layer
That division of labor matters because it prevents an expensive design mistake. You do not need to place all of your data on high-memory systems just to support a smaller set of fast workloads. You can keep historical data in a lower-cost distributed store, then run Spark only where speed changes the business outcome.
For a business leader, the easiest way to read this model is by role. Hadoop is the long-hold foundation. Spark is the fast-turn execution layer. Used together, they let one platform serve both cost control and responsiveness.
| Business need | Best fit in the hybrid model |
|---|---|
| Long-term data retention | Hadoop HDFS |
| Shared cluster scheduling | YARN |
| Interactive analysis | Spark |
| Streaming data pipelines | Spark |
| Historical archives | Hadoop |
| ML experimentation and feature preparation | Spark |
This hybrid approach also gives architecture teams more room to modernize in stages. A company does not have to rebuild everything at once. It can keep stable storage and governance patterns in place, introduce Spark for the workloads that need faster iteration, and choose infrastructure based on budget, performance targets, and available cloud hosting options.
A retail example makes this concrete. An ecommerce company may retain years of orders, catalog changes, and clickstream events in Hadoop-backed storage for reporting, auditing, and model training. Spark can then process fresh browsing sessions and recent transactions to update recommendations or detect unusual buying behavior while the customer is still active.
The same pattern works well in financial services. Large reporting datasets can stay in Hadoop for retention and compliance workflows. Spark can process incoming events fast enough to support fraud checks, operational alerts, or model refresh cycles that depend on current data instead of last night's batch.
That is why Spark and Hadoop still belong in the same modernization conversation. One keeps the economics of large-scale data manageable. The other helps teams turn that data into timely decisions for analytics and AI. Once that data foundation is in place, the next challenge becomes operational. Teams also need systems to govern prompts, workflows, and application behavior so AI uses that data safely and consistently.
Choosing Your Engine Performance Speed vs Infrastructure Cost
A leadership team usually feels this decision in one place first. The quarterly budget meeting.
One group wants faster model training, quicker dashboards, and fraud checks that happen while a transaction is still in motion. Another group sees the infrastructure bill and asks a fair question. Do we need a high-performance engine for every workload, or only for the few that create immediate business value?
That is the primary tradeoff. Spark often wins on speed. Hadoop often wins on storage economics. The better choice depends on whether your constraint is time, cost, or both.
Spark vs Hadoop at a glance
| Criterion | Apache Hadoop (MapReduce) | Apache Spark |
|---|---|---|
| Core strength | Distributed storage and batch processing | Fast large-scale processing and analytics |
| Processing style | Disk-centric MapReduce | In-memory processing with flexible scheduling |
| Best fit | Massive, static, long-running batch workloads | Iterative analytics, machine learning, interactive and streaming work |
| Speed | Slower for repeated multi-step jobs | Can outperform Hadoop MapReduce by up to 100 times in-memory and 10 times on disk, according to Logz.io’s Hadoop vs Spark benchmark summary |
| Storage economics | More cost-effective for large-scale storage on commodity hardware | More RAM-intensive, often more expensive per node |
| Recovery model | Resumes from failure point in its processing model | Rebuilds from lineage unless checkpointed |
| Typical role | Durable data backbone | Acceleration engine |
What speed actually buys the business
Spark is often the better fit when teams need to revisit the same data repeatedly. That happens in recommendation systems, feature engineering, anomaly detection, and model training loops. In those cases, waiting on disk-heavy batch cycles slows down product decisions, customer responses, and analyst iteration.
A simple way to frame it is this. Hadoop MapReduce works like a freight rail system built for huge loads at a low cost per trip. Spark works like an express network that costs more to run but gets high-priority work to the destination much faster.
That difference matters most when speed changes an outcome. If a fraud model updates in minutes instead of hours, losses can drop. If product teams test customer behavior faster, they can ship AI-assisted features sooner. If finance gets the same report tomorrow instead of right now, Spark may not justify the extra spend.
What infrastructure cost actually buys the business
Hadoop stays attractive because many enterprises are not short on data. They are short on affordable ways to keep years of it available for reporting, compliance, retraining, and audit history.
Spark uses memory aggressively to get better performance. That can raise per-node costs, especially if teams size clusters for peak demand instead of actual workload patterns. Hadoop’s disk-oriented approach is usually easier to justify when data is large, relatively stable, and processed on a schedule.
This is where architecture discipline matters. A faster engine is only a good investment when it improves a business metric such as conversion, customer retention, fraud prevention, service response time, or developer throughput.
A practical decision framework for enterprise leaders
Use this lens when choosing where to place a workload:
- Choose Hadoop-first for archival-scale storage, long retention periods, overnight batch jobs, and workloads where low-cost infrastructure matters more than fast iteration.
- Choose Spark-first for machine learning pipelines, repeated transformations, interactive analytics, streaming data, and AI applications that need current answers.
- Choose hybrid when data has a long economic life but only part of it needs fast processing. That is common in enterprises modernizing toward AI.
A retailer is a good example. Years of order history, returns, and catalog changes may live in lower-cost Hadoop-oriented storage. Spark can process the latest browsing and transaction activity to update recommendations while a customer is still shopping. You keep storage costs under control without forcing every AI workload through a slow batch cycle.
The mistake to avoid
The common mistake is treating this as a winner-take-all decision.
For most enterprises, it is a portfolio decision. Some workloads are infrastructure-heavy and cost-sensitive. Others are decision-heavy and time-sensitive. Good architecture separates those two instead of paying premium compute rates for everything or forcing latency-sensitive work into a batch system.
If your team is still aligning platform choices with growth plans, compliance needs, and cloud hosting options, make that comparison workload by workload rather than platform by platform.
One more factor: AI modernization is not only about compute
Once leaders choose the right engine mix, the next operational question appears quickly. How do teams manage the AI workflows built on top of that data foundation?
Spark can shorten the path from raw data to model features, retrieval pipelines, and near-real-time application behavior. Hadoop can keep historical data available at a manageable cost. But AI modernization also introduces prompt versioning, workflow governance, evaluation, and rollback concerns. Those planning changes across systems, teams, and dependencies should treat the platform decision as part of a broader modernization effort and follow a database migration planning approach that accounts for reliability and rollback.
Deployment Patterns and Migration Strategies
A migration plan should start with the business constraint, not the tool name.
Some teams are building a new data platform for a new product. Others are carrying years of Hadoop jobs that feed finance reports, compliance processes, and customer-facing systems. Those are two very different starting points, and treating them the same usually leads to unnecessary risk, higher cost, or both.
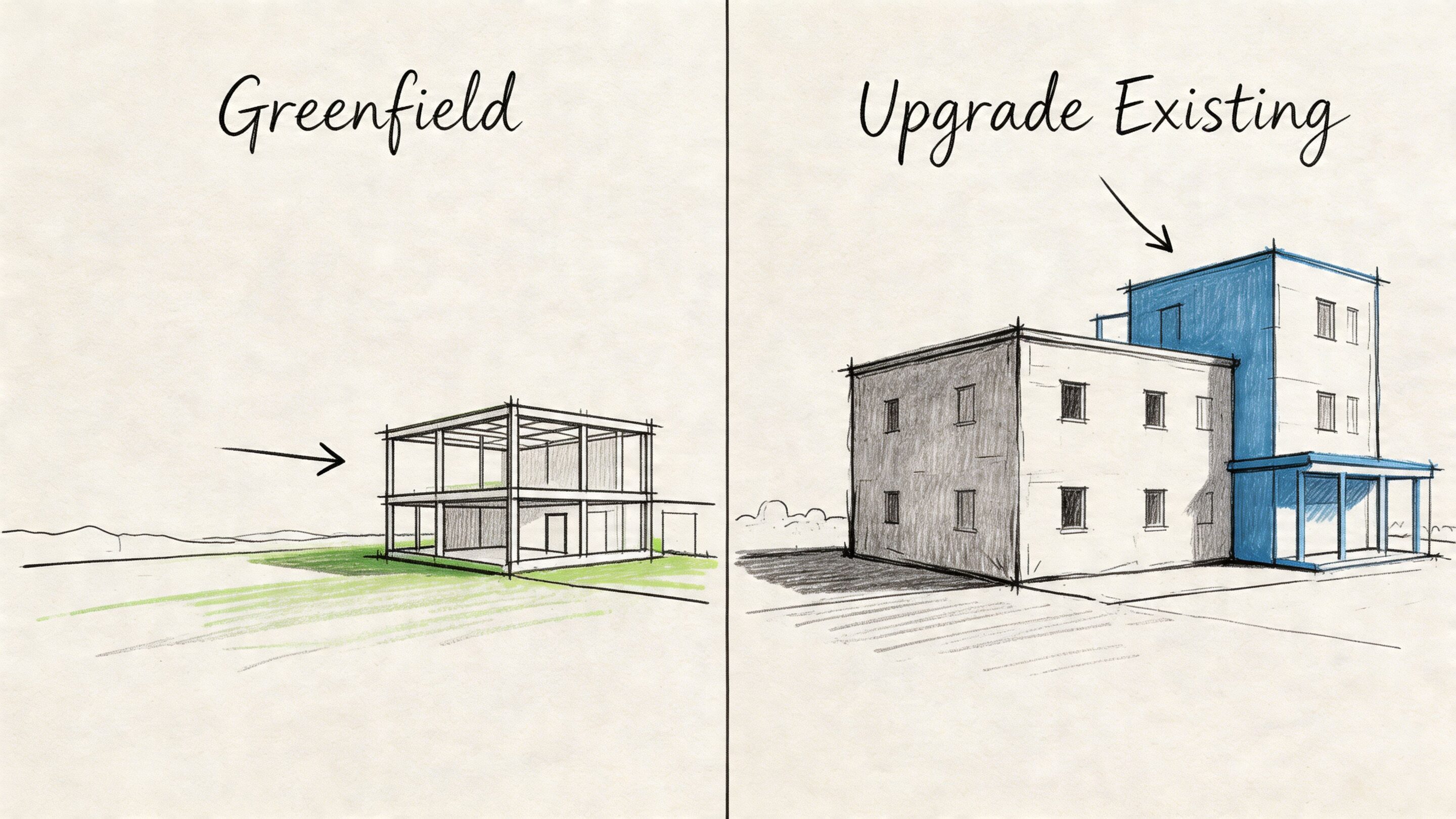
Greenfield versus brownfield
A greenfield deployment fits a team launching a new AI feature, creating a fresh analytics environment, or rebuilding a platform whose old design no longer matches how the business operates. In that case, leaders have more freedom to choose the right mix of storage, processing, and governance from the beginning.
A brownfield deployment is the more common enterprise story. You already have Hadoop clusters, HDFS data, and scheduled jobs that other systems depend on. Spark often works best here as a new compute layer added on top of existing data and infrastructure, not as a full replacement on day one.
That approach is usually easier to explain to business stakeholders. It works like renovating a working warehouse instead of tearing it down while orders are still shipping. You improve the lanes that create the most delay first, while the rest of the operation keeps running.
For teams mapping that transition, Wonderment’s guide to database migration best practices for reliability and rollback planning is a helpful companion because the hard part is rarely compute alone. Schema design, system dependencies, testing, and recovery planning often determine whether the migration succeeds.
A sensible migration pattern
The strongest migration programs usually begin with one question. Which workload causes the most business friction relative to the effort required to improve it?
That framing keeps the program grounded in outcomes. If a nightly pipeline delays finance reporting, product analytics, or feature generation for AI systems, it is a better first candidate than a firmly embedded legacy workflow with many downstream dependencies.
A practical sequence often looks like this:
Find jobs that create visible delay
Focus on workflows that run long, deliver data late, or force teams to wait for reports, models, or application updates.Move transformation-heavy and iterative workloads first
Spark tends to show value fastest where jobs involve repeated processing, interactive analysis, or machine learning preparation.Keep existing Hadoop components that still serve a purpose
If HDFS and YARN are already handling storage and resource coordination well, keep using them while modernizing the processing layer.Design recovery before production cutover
Sensitive workflows need clear checkpointing, restart behavior, and rollback rules before they carry revenue, compliance, or customer experience impact.
Architecture note: Good migration reduces operational risk while improving speed. If the plan requires every team to relearn the platform at once, the plan is too broad.
Where migrations usually get expensive
The common cost problem is not adopting Spark. It is adopting Spark without enough operational discipline.
Spark on YARN can run well in an existing Hadoop environment, but poor executor sizing, memory allocation, and cluster isolation can erase the performance gains leaders expected to buy. In business terms, the company pays for a faster engine and then runs it with the parking brake on.
Watch for these warning signs:
- Executors run short on memory: jobs become unstable, retries increase, and processing windows stretch.
- Shared clusters have weak guardrails: one noisy workload affects another, which makes delivery times hard to predict.
- Default settings stay in place too long: production workloads usually need tuning based on actual data size and job shape.
- Recovery behavior is not agreed on: engineering, operations, and compliance may all expect different outcomes after a failure.
Fault tolerance is also a governance choice
Hadoop and Spark recover from failure in different ways, and that difference matters most in regulated or high-trust environments.
Hadoop’s model can be a better fit for long-running batch processes where deterministic restart behavior supports auditability. Spark often reconstructs lost data through lineage unless teams add checkpointing. For AI modernization, that design choice affects more than uptime. It shapes how confidently teams can support model training pipelines, retrieval workflows, and business processes that depend on repeatable outputs.
For a business leader, the practical question is straightforward. Do you need the lowest-cost platform for large-scale historical processing, the fastest path for iterative analytics and AI features, or a hybrid model that balances both? In many enterprises, the best migration path is hybrid. Hadoop continues to carry durable, cost-sensitive workloads, while Spark accelerates the data products and AI workflows that benefit from faster iteration.
Real-World Use Cases for Enterprise Teams
Architecture gets easier to understand when you attach it to a business moment instead of a technology diagram.
Ecommerce and retail
A retailer wants to improve recommendations during active browsing, not after the shopper has left.
Spark fits the fast path. It can process recent behavior, product affinity signals, and pricing context quickly enough to support timely personalization. Hadoop remains useful in the background for broader inventory analysis, historical order patterns, and large-scale data retention.
The result is a system where real-time experience and long-term planning don’t compete for the same engine.
Fintech and SaaS
A payments platform wants to react to suspicious activity while preserving reliable end-of-day reporting.
That split is common. Spark handles fast-moving operational analysis well, especially where teams need low-latency processing. Hadoop supports durable storage and scheduled reporting workloads that demand consistency and scale.
Fast decisioning and dependable reporting often belong in the same business process, but not in the same processing style.
For SaaS teams, the same pattern applies to tenant analytics, feature telemetry, and platform operations. One layer supports live insight. Another supports durable history.
Healthcare and wellness
A healthcare organization may need near-real-time monitoring in one workflow and long-term archival in another.
Spark makes sense where incoming data must be processed quickly for operational use. Hadoop makes sense for storing large volumes of records that need resilient, low-cost retention and structured access patterns over time.
In this environment, recovery behavior and governance are just as important as speed. Teams need to align platform choices with workflow sensitivity, not only performance goals.
Media and content platforms
Media companies often run two very different data motions at once.
They personalize feeds, rank content, and analyze fresh engagement signals on one side. On the other, they process large logs, historical engagement archives, and content libraries at scale. Spark helps with the dynamic side. Hadoop supports the heavy archival and batch side.
The pattern behind all of these
Business value comes from assigning the right work to the right engine.
- Use Spark for fast, iterative, user-facing intelligence
- Use Hadoop for durable, economical, large-scale storage and batch operations
- Combine them when the product needs both
That’s why spark and hadoop continue to show up in enterprise modernization conversations. They map well to how large organizations work.
Modernizing Your Data Stack for the AI Era
A common enterprise scenario looks like this. The data team finishes a Spark and Hadoop modernization project, the first AI pilot shows promise, and leadership expects the business to scale that success across products. Then progress slows. The problem is no longer storing data or processing it fast enough. The problem is operating AI safely, predictably, and at a cost the business can control.
That shift matters because Spark and Hadoop solve the foundation layer, not the full operating model. Spark helps teams process and prepare data quickly. Hadoop helps retain large volumes of data economically over time. Once those pieces are in place, the next set of decisions moves up the stack. Leaders have to decide how prompts are managed, how model behavior is tracked, how usage is audited, and how AI features are governed across real applications.
Teams modernizing toward cloud-native application architecture feel this pressure first. A cloud-native system makes it easier to release AI features across services, customer workflows, and internal tools. It also creates more places where costs can spread, prompts can drift, and model decisions can become difficult to trace.
The easiest way to explain it is to compare AI modernization to building a new distribution network. Spark and Hadoop help you move raw materials and store inventory efficiently. They do not replace the control tower that tracks what was shipped, which route was used, what it cost, and where problems started.
For that reason, a serious AI application stack usually needs four operational controls:
- Prompt versioning so teams can tie outputs to the exact prompt used in production
- Parameter management so applications can control how models interact with internal systems and data
- Unified logging so engineering and compliance teams can trace behavior across AI services
- Cost visibility so product and finance leaders can see where model usage is rising before budgets drift
Without those controls, AI work often spreads faster than governance. One team changes a prompt. Another adjusts retrieval settings. A third ships a new model endpoint. The feature may still work, but no one can explain why quality changed, why spend increased, or where a risky response originated.
Staffing changes too. Data modernization for AI usually requires a mix of platform engineering, application engineering, and model-aware development. If your roadmap depends heavily on Python for data pipelines, APIs, and AI services, it helps to understand the market for hire python developers so hiring plans match the architecture you are building.
The business question is broader than "Spark or Hadoop?" Senior leaders get better results by asking four practical questions:
- Where does the business need faster decision cycles?
- Where does it need lower-cost long-term retention?
- Which workloads belong in batch, streaming, or iterative processing?
- What operating controls will keep AI features reliable once they reach production?
That is the essential modernization path for the AI era. Use Spark where speed creates business value. Use Hadoop where scale and storage economics matter. Combine them where both are needed. Then add the application and governance layer that keeps AI from turning into an expensive collection of disconnected experiments.
If you're planning that next step, Wonderment Apps can help you modernize the full path from data foundation to AI operations. Their team builds scalable web and mobile products, integrates AI into existing software, and offers a prompt management system with a versioned prompt vault, parameter controls for internal database access, unified logging across integrated AI services, and cost tracking for cumulative model spend. If you want to see how that fits into your current stack, request a demo and start with a practical architecture conversation.