
You’ve probably reached the awkward middle stage of product growth.
The app works. Customers are using it. Internal stakeholders keep asking for AI features, cleaner workflows, better reporting, stronger performance, and fewer bugs. At the same time, your in-house team is stuck doing the unglamorous work that keeps the lights on. Every sprint turns into maintenance triage.
That’s usually when the conversation around hiring dedicated development team support stops being theoretical. It becomes operational. You need more shipping capacity, but you also need judgment, continuity, and a way to modernize the product without turning delivery into chaos.
Your Scaling Pains Are Real but Your Options Are Better
When a product starts to grow, engineering pressure shows up in strange places first. It’s not always a full outage or a dramatic system failure. More often, it looks like a queue of “important but not urgent” work that never gets done. AI copilots stay in prototype mode. Personalization ideas live in slides. Infrastructure upgrades keep slipping behind customer-facing tickets.
That’s the point where a dedicated team starts making sense as a strategic move, not a budget trick.
Why companies use this model
Big companies didn’t adopt dedicated teams by accident. 92% of Forbes Global 2000 companies engage in IT outsourcing with dedicated development teams as a primary model for maintaining competitive velocity in 2025, alongside 37% of small businesses (AgileEngine).
That tells you something important. This model isn’t just for startups trying to save cash. Mature companies use it because delivery stalls when hiring can’t keep pace with roadmap demands.
A good dedicated team gives you a stable group that works inside your planning rhythm, your architecture decisions, and your release process. That’s very different from tossing requirements over the wall to a vendor and hoping for a clean handoff later.
The modern bottleneck isn’t just coding
Plenty of leaders still frame the problem as “we need more developers.” Usually, that’s incomplete.
You often need a team that can handle several things at once:
- Application scaling: Performance tuning, backend resilience, and architecture decisions that support a larger user base.
- AI modernization: Integrating language models, recommendation systems, automation layers, and governance around them.
- Product continuity: Shipping new features without draining the core team’s attention from existing customers.
- Operational discipline: Managing prompts, logs, model behavior, and spend in a way the business can govern.
Practical rule: If your roadmap includes AI, don’t hire only for feature velocity. Hire for operational control too.
That last point gets ignored too often. AI work creates new administrative needs from day one. Teams need a way to organize prompts, version changes, control how parameters reach internal data, track model outputs, and keep an eye on cumulative usage costs. Without that backbone, even skilled engineers end up improvising governance.
What works and what doesn’t
What works is treating the dedicated team as part of the product organization. They need access to context, not just tickets.
What doesn’t work is using the model as a pressure release valve while keeping all product knowledge locked inside the internal team. That creates dependency, slow approvals, and expensive misunderstandings.
The strongest engagements usually start with a simple belief: your internal team shouldn’t have to choose between maintaining the current product and building the next version of it.
When a Dedicated Team Is Your Winning Move
Not every software initiative needs a dedicated team. Some need a sharp discovery project. Some need one specialist for a short burst. Some need a managed delivery partner with clear output ownership.
But some projects are a poor fit for short-term staffing from the very beginning.
The strongest fit
A dedicated team is usually the right call when the roadmap keeps moving while the product is already live. If the work will evolve based on user behavior, technical findings, stakeholder input, or AI model iteration, rigid project scoping tends to break down fast.
There’s also a simple benchmark that matters. Long-term projects lasting more than 6 months see 100% focus yielding quicker feature implementation, outperforming project-based models by 20-30% in velocity (Designli).
That advantage comes from continuity. The team doesn’t keep re-learning your app, your users, your architecture, and your constraints.
A quick comparison
| Model | Best fit | Weak spot |
|---|---|---|
| Dedicated team | Evolving roadmap, live product, AI modernization, ongoing scale work | Requires active client involvement |
| Fixed-price project | Tight scope, clear deliverables, short implementation | Struggles when requirements move |
| Staff augmentation | You already have strong delivery management and need extra hands | Can create fragmented ownership |
If you’re weighing dedicated teams against other models, this breakdown on staff augmentation vs managed services is useful because it highlights the management burden each option places on your side.
Signals that you should not force fixed-price
Some clients try to lock down a fixed project because it feels safer. Sometimes that works. Often it creates false certainty.
A dedicated team is usually the smarter move when your project includes any of these conditions:
- AI features with iteration loops: Prompt behavior, model selection, fallback logic, and logging usually need refinement after release.
- Deep business logic: Fintech, healthcare, retail operations, and workflow-heavy SaaS products rarely fit neatly into a frozen scope.
- Platform work plus feature work: You’re improving reliability, observability, and scale while adding new capabilities.
- Cross-functional dependencies: Design, engineering, QA, product, and compliance all need regular coordination.
- Long-lived ownership: The software will keep evolving after the first release.
A dedicated team makes the most sense when learning is part of the delivery plan, not a surprise that appears halfway through.
Where staff augmentation falls short
Staff augmentation can be effective if you already run a disciplined engineering organization and need capacity. But if your internal leads are already overloaded, adding individual contributors may increase coordination overhead instead of reducing it.
That’s where dedicated teams become more useful. You’re not just getting talent. You’re getting a delivery unit that can absorb product context together.
Good candidates for this model
This model tends to perform well for:
- Ecommerce teams rolling out personalization, subscriptions, order workflows, or AI-assisted merchandising
- Fintech products with secure user journeys, compliance-sensitive logic, and steady release pressure
- Healthcare platforms where continuity matters because the application can’t afford context loss
- SaaS companies balancing feature requests with architecture cleanup and scale demands
- Media products that need performance, content operations, and experimentation
The wrong use case is usually short, isolated work. If you need a one-off build with a narrow scope and a hard stop, a dedicated team can be too much structure for too little runway.
Assembling Your A-Team and Sourcing Talent
Once you decide the model fits, the next mistake is rushing into provider demos before defining the actual team shape. That’s how companies end up overbuying seniority in one area and underbuying critical support roles somewhere else.
A dedicated team should match the product problem, not a generic engineering org chart.

Start with the work, not the resumes
The talent market is tight enough that waiting for the “perfect” local hire often costs more than leaders expect. A projected global shortage of 85 million developers by 2030, plus average in-house recruitment costs of $3,500 per hire and $1,100 in training, is one reason companies use dedicated team models instead (Instinctools).
That pressure changes how smart buyers hire. They define outcomes first, then build the role mix backward from the roadmap.
A practical way to scope the team is to answer four questions:
- What must ship in the next two quarters?
- What technical debt will block that roadmap if ignored?
- What AI or data work needs specialized experience?
- Which parts of the product demand business-context continuity?
Typical team shapes
You don’t need every role on day one. But you do need the right spine.
Product-led app team
This setup fits many web and mobile products:
- Product or project lead to manage priorities, dependencies, and decisions
- Frontend engineer for customer-facing experience
- Backend engineer for APIs, business logic, and integrations
- QA engineer to protect release quality
- UX or product designer when workflows are changing, not just screens
AI modernization team
When the roadmap includes AI, the shape shifts:
- Application engineer to wire AI into the product
- Backend engineer to manage orchestration, auth, and data flow
- QA specialist focused on edge cases and output validation
- Product lead who can define acceptable model behavior
- Optional data or prompt operations support if the AI layer will expand quickly
Scale and reliability team
For products already under load, you may need:
- Senior backend or platform engineer
- DevOps or cloud-focused engineer
- QA automation support
- Delivery lead to keep reliability work visible alongside features
How to vet a partner without getting distracted by polish
Sales decks are easy to produce. Stable teams are harder.
Use interviews to get specific. Ask how the provider recruits, how they replace people, how they preserve knowledge, and how they evaluate domain readiness in industries like healthcare, ecommerce, or fintech.
A useful shortlist of questions:
- Who interviews the developers before they join client work?
- Can we meet proposed team members before kickoff?
- How do you handle underperformance or role mismatch?
- What does your onboarding process look like?
- How do you document decisions so knowledge stays with the team?
- What experience do these people have with our stack and industry constraints?
- How do you support AI integration, logging, and operational governance?
If you want a practical recruiting lens from the buyer side, how to recruit the best talent in tech tips tricks is worth reviewing before provider calls.
Green flags and red flags
| Green flags | Red flags |
|---|---|
| You can interview the actual team | You only meet sales and account staff |
| The provider asks detailed product questions | The provider pushes a prepackaged team immediately |
| They discuss QA, documentation, and delivery rituals | They focus only on coding speed |
| They explain how knowledge stays durable | They treat staffing as interchangeable |
| They speak plainly about trade-offs | They promise frictionless delivery |
The best providers don’t sound easy. They sound prepared.
Where to look for talent signals
Even if you’re hiring through a partner, it helps to understand what strong remote talent looks like in the open market. Browsing curated boards like find remote jobs can give you a better feel for role expectations, stack specialization, and how experienced candidates present their strengths.
That doesn’t replace provider vetting. It sharpens your questions.
A final note. Don’t choose a partner because they can staff fast alone. Choose them because the people they staff can stay effective after the first sprint, when novelty disappears and real product work begins.
Navigating Contracts and Powering Up Onboarding
A dedicated team relationship gets expensive when the contract is vague and onboarding is rushed. Most delivery problems that show up in month three originated in week one.
The agreement should protect the relationship. The onboarding should make it usable.
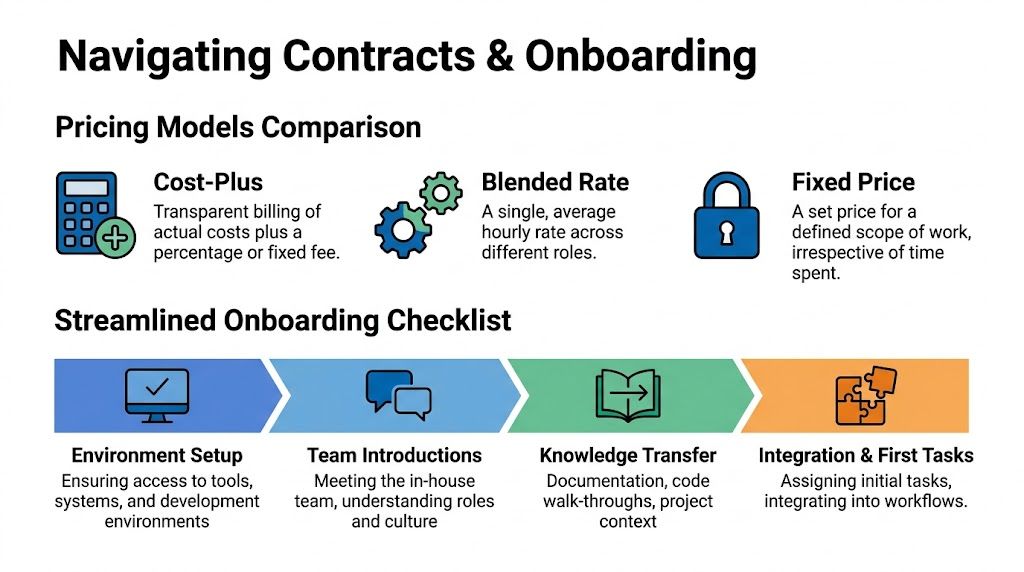
Choose a pricing model that matches reality
Leaders often ask which pricing model is best. The better question is which model best matches how much uncertainty still exists in the work.
Cost-plus
This model works when transparency matters more than a neat packaging of effort. You pay for actual delivery costs plus an agreed fee structure.
Good fit: evolving products, specialized roles, unclear delivery path.
Blended rate
A blended rate simplifies budgeting by applying one average rate across roles. That can be helpful when you want smoother financial planning and don’t want every staffing change to trigger a pricing conversation.
Good fit: stable cross-functional teams with changing sprint makeup.
Fixed price
Fixed price only works when scope is clearly defined. It can be useful for contained milestones, migrations with clear boundaries, or narrow implementations.
Bad fit: AI work, exploratory product changes, or any roadmap that will shift with feedback.
Contract clauses worth reading twice
Don’t skim these.
- IP ownership: The contract should state clearly that code, designs, documentation, and deliverables belong to your company.
- Access and security obligations: Define how environments, credentials, and sensitive systems are handled.
- Replacement terms: Spell out what happens if a team member isn’t the right fit.
- Termination mechanics: Make sure notice periods and transition duties are reasonable.
- Knowledge transfer requirements: If the engagement ends, the handoff should be part of the agreement, not a favor.
- Working model and communication expectations: Set the basics for reporting, planning, demos, and escalation.
For a sharper contract review lens, these questions you should ask before hiring outsourcing companies will save you from vague language that sounds harmless until something goes wrong.
Onboarding needs structure
Here’s the operational reality. Effective onboarding typically requires 2-4 weeks for full integration, and ongoing management demands 15-20 hours of client oversight weekly to prevent communication gaps and keep KPIs aligned (Meduzzen).
That number surprises people. It shouldn’t. A dedicated team isn’t plug-and-play. It becomes productive because both sides invest in making context shareable.
Operator note: If no one on your side owns onboarding, the team will invent its own assumptions.
A first-month checklist
Environment and access
Give the team access to the systems they need, in the order they need them. Repos, staging, project boards, documentation, communication channels, analytics views, and testing tools should be mapped before kickoff.
Product and domain context
Run live walkthroughs. Don’t rely only on old documentation. Show current workflows, problem areas, customer pain points, release risks, and known architectural weak spots.
Team integration
Introduce stakeholders by role, not just by name. Everyone should know who approves requirements, who answers compliance questions, who owns analytics, and who breaks ties when priorities conflict.
First tasks
Start with meaningful work, but not the riskiest work. Early tickets should expose the team to your codebase, process, and review standards without making the first sprint a referendum on their value.
A broad people-operations checklist like 10 Employee Onboarding Best Practices can also help internal leaders think more systematically about integration, expectations, and early communication habits.
Good onboarding feels deliberate. That’s the point. The more clearly you define access, authority, and context early, the less time your team spends guessing later.
Driving Success with Modern Governance and Tooling
Hiring the team isn’t the finish line. The teams that produce durable outcomes are governed well.
That doesn’t mean hovering over standups or measuring people by raw activity. It means creating a delivery system where decisions are visible, quality is inspectable, and AI behavior is managed like a product concern instead of an experiment hidden in code.
Good governance is specific
Weak governance usually sounds like this: “Keep us updated.”
Strong governance sounds more like this:
- What counts as done for an AI-assisted workflow?
- Which defects block release versus enter backlog?
- Who approves prompt changes in production?
- Where do architecture decisions get documented?
- What signals tell us the team is healthy or drifting?
That’s where KPIs matter, but only if they’re attached to product reality.
A sensible set often includes sprint predictability, defect escape patterns, cycle bottlenecks, code review discipline, and release confidence. For AI work, teams also need clear operational checkpoints around prompt changes, model behavior, logging, and usage oversight.
Metrics that help and metrics that waste time
| Helpful metrics | Weak metrics |
|---|---|
| Sprint commitment reliability | Hours spent online |
| Defect trends by severity | Number of messages sent |
| Review turnaround and merge flow | Raw line count |
| Release readiness and rollback frequency | Ticket volume without context |
| Prompt change traceability for AI features | “Busyness” indicators |
You’re looking for evidence that the team can ship responsibly, not evidence that they look busy on dashboards.
AI changes the operating model
Traditional app development already needs governance. AI adds a second layer.
Once your product uses language models or similar systems, the team needs a repeatable way to manage prompts, version updates, internal parameters, logs, and usage costs. Otherwise, you get exactly the kind of mess that makes executives lose trust in AI projects. Nobody knows which prompt caused a bad output. Nobody knows whether a cost spike came from one workflow or five. Nobody can explain why two users got different answers for the same task.
Teams build faster when prompt logic is treated like application logic, not hidden configuration.
That’s why administrative tooling matters so much. Tools like Jira, GitHub, Linear, Datadog, and product analytics platforms help manage software delivery. AI-integrated products also need dedicated operational controls for the model layer itself.
One option in that category is Wonderment Apps’ prompt management system, which includes a prompt vault with versioning, a parameter manager for internal database access, a logging system across integrated AIs, and a cost manager that gives entrepreneurs visibility into cumulative spend. Used properly, that kind of tooling gives a dedicated team a governed environment for AI modernization instead of forcing them to stitch together oversight manually.
The management pattern that tends to work
High-functioning client teams usually do a few things consistently:
Keep one source of truth
Requirements, acceptance criteria, prompt policies, design decisions, and architecture notes should live in known systems. If decisions happen only in meetings, they disappear.
Review demos against outcomes
A sprint demo shouldn’t be theater. It should answer whether the team solved the intended user or business problem.
Separate product debate from execution churn
If every sprint includes unresolved arguments about strategy, the team can’t maintain momentum. Product leadership has to make decisions fast enough for engineering to move.
Audit AI behavior as part of release readiness
For AI-enabled features, teams should review not only whether the feature works, but whether outputs are traceable, prompts are current, and usage is understandable.
When governance and tooling line up, dedicated teams stop feeling “external.” They become legible. That’s what most leaders want: not more activity, but more confidence.
Common Pitfalls and How to Sidestep Them
A lot of advice about dedicated teams focuses on obvious issues like time zones and communication style. Those matter, but they’re rarely the reason a promising engagement fails.
The bigger problems are subtler. They build slowly, then show up all at once in missed releases, brittle knowledge transfer, and awkward conversations about accountability.
The most expensive assumption
The common assumption is that if the provider is good, the model will take care of itself. It won’t.
A dedicated team can still fail when the client treats the group like a disposable vendor layer instead of a product partner. People stop sharing context. Requirements arrive late. QA gets squeezed. Domain knowledge lives in private messages and hallway conversations.
That’s how avoidable rework starts.
Turnover is the hidden operational risk
In regulated products, team continuity matters more than many buyers realize. A hidden risk in dedicated teams is high turnover, averaging 15-20% annually in offshore teams, which can be especially damaging in fintech and healthcare, and post-2025 AI ethics regulations will further demand auditable team continuity (Wezom).
That issue is bigger than staffing inconvenience. In healthcare, fintech, and compliance-heavy commerce, rotating people in and out without disciplined handoff can create gaps in security understanding, release judgment, and audit readiness.
How to reduce the failure modes
Don’t let knowledge stay tribal
Require living documentation, architecture notes, decision logs, and clear acceptance criteria. If the only person who understands a workflow is one engineer, you don’t have a delivery system. You have a liability.
Build continuity into the contract
Ask about retention practices, backup coverage, role shadowing, and handoff expectations. If continuity matters to your product, make it part of the commercial conversation.
Treat the team like insiders
Bring them into sprint reviews, roadmap context, user feedback, and post-release analysis. Teams make better decisions when they understand why the work matters.
Watch for slow cultural drift
A project can look fine in dashboards while trust is eroding. Pay attention to hesitation in meetings, passive agreement, poor escalation habits, and recurring misunderstandings around ownership.
If your dedicated team never pushes back, they probably don’t have enough context or enough psychological safety.
Match the model to the work
Short, isolated tasks often do better with project delivery or specialist support. Dedicated teams perform best when continuity has real value.
One practical habit helps with nearly all of this: review the engagement monthly at the operating-model level, not just the backlog level. Ask whether the team has enough context, whether decisions are documented, whether AI changes are governed, and whether knowledge would survive a staffing change. That check catches problems long before they become expensive.
Your Questions Answered Hiring a Dedicated Team
Who owns the IP created by the team
Your company should own the IP. That needs to be explicit in the contract. Don’t rely on assumptions or informal emails. Code, designs, prompts, documentation, and deliverables should be clearly assigned to you.
What if someone on the team isn’t performing
Handle it quickly and directly. Good partners should have a defined process for feedback, performance correction, and replacement if needed. The mistake is waiting too long because you hope things improve on their own.
How do we bring knowledge back in-house later
Plan for that from the start. Require documentation, code review visibility, recorded walkthroughs where appropriate, architecture notes, and shared ticket history. A clean exit is easier when the team has been working transparently the whole time.
How do you handle security and compliance
Use role-based access, environment separation, documented approval paths, and clear policies around sensitive data. In regulated products, involve compliance stakeholders early instead of reviewing everything at the end.
How much management should we expect on our side
More than zero, less than full operational burden. Dedicated teams work best when the client provides product clarity, timely decisions, and active participation in planning and review rhythms.
If you’re evaluating a dedicated team for AI modernization, scalable app delivery, or a product that needs more than extra hands, Wonderment Apps can help you think through team shape, governance, and how to support AI features with the right prompt, logging, and cost controls from the start.