
A lot of commerce teams hit the same wall at the same time. Marketing wants faster campaign launches, product wants richer mobile experiences, support wants cleaner account flows, and engineering is still waiting on a platform release window that touches everything from templates to checkout behavior.
That's when the architecture stops being an IT concern and becomes a growth constraint.
If your storefront, content, catalog, and customer experience logic are locked inside one monolithic stack, every change carries too much risk. Small updates become coordinated projects. Peak traffic creates anxiety. AI ideas like smarter search, recommendations, or support assistants sound exciting in workshops, then stall in implementation because the underlying platform can't expose the right data cleanly enough.
Is Your Commerce Platform Holding You Back
A familiar pattern shows up in boardrooms and sprint reviews alike. The business has solid products, decent traffic, and a roadmap full of ideas. But the platform can't keep up.
The homepage redesign is delayed because it depends on backend release timing. The mobile app team can't reuse enough commerce logic cleanly. Merchandising wants richer product storytelling, but content changes still run through engineering. Then a seasonal spike arrives and everyone stares at dashboards, hoping the platform behaves.
Where monoliths start to hurt
The problem usually isn't that the current platform is broken. It's that it was built for a different era of digital commerce.
In a tightly coupled system, the frontend experience and backend commerce engine move together. That sounds neat until your teams need to move at different speeds. A content editor wants same-day updates. A frontend team wants to ship a React or Vue experience. A backend team needs stability around pricing, inventory, and order processing. One stack, one release rhythm, one bottleneck.
Practical rule: When every customer-facing change requires backend coordination, your architecture is already slowing revenue work.
This is why headless commerce architecture has moved from niche to mainstream. As of 2025, 73% of businesses have adopted headless commerce architecture, with the market projected to expand from $1.74 billion in 2025 to $7.16 billion by 2032, according to Envive's headless commerce statistics roundup.
That shift reflects a simple business reality. Companies want freedom to improve the customer experience without rewriting the commerce engine every time they change the interface.
Why this matters beyond web redesign
The biggest mistake I see is treating headless as a frontend project. It isn't. It's an operating model change.
A decoupled architecture gives teams room to build for web, mobile, in-store, and emerging interfaces without forcing every channel through the same presentation layer. It also creates a cleaner foundation for AI. Recommendation systems, AI-assisted search, dynamic merchandising, support copilots, and internal merchandising tools all depend on accessible APIs, structured data, and predictable integration points.
That's where the next layer of complexity shows up. Once you modernize the stack, you also need a reliable way to manage application intelligence itself. AI features don't stay manageable for long if prompts, parameters, logs, and usage costs are scattered across codebases and dashboards. The companies that modernize well usually solve both problems together. They upgrade the architecture and put governance around the intelligence they're adding to it.
Understanding Headless Commerce The Core Concept
The easiest way to explain headless commerce is with a restaurant.
The customer sits in the dining room. The kitchen prepares the meal. The waiter carries requests and responses between them. The dining room can change its decor, layout, or service style without rebuilding the kitchen. The kitchen can improve how it prepares food without redesigning the tables.
That's what headless commerce architecture does.
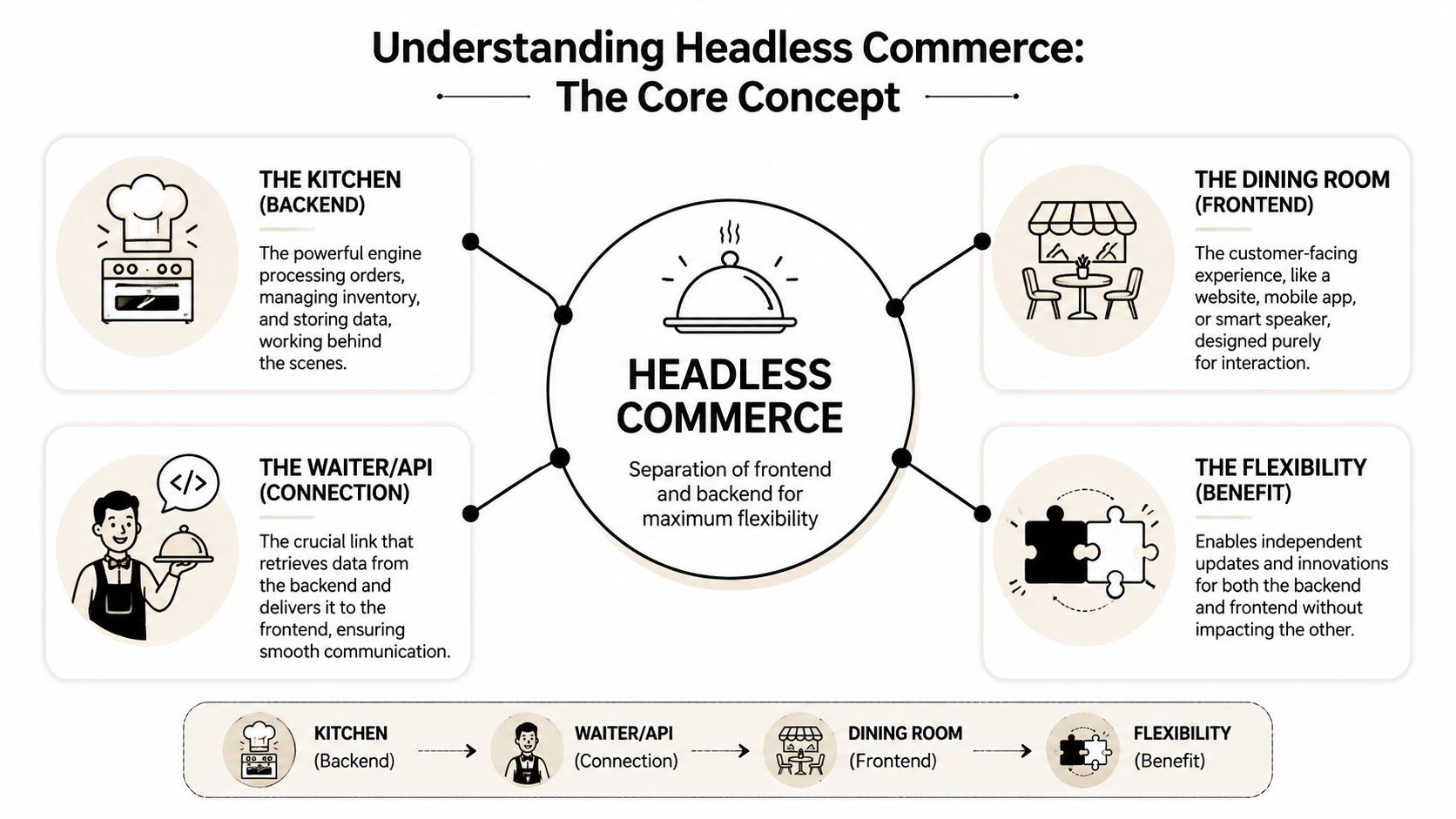
The dining room, the kitchen, and the waiter
In this model, the frontend is the dining room. It's the customer-facing experience. That can be a website, mobile app, PWA, kiosk, smart mirror, voice assistant, or social shopping interface, as outlined in Yotpo's explanation of headless commerce.
The backend is the kitchen. It handles the serious work. Product information, pricing, promotions, customer accounts, inventory, checkout, payments, and order logic all live there.
The API layer is the waiter. It takes requests from the frontend and returns the data or action the experience needs. That API layer is what makes the separation work. The frontend doesn't need to know how the backend is built. It just needs a reliable contract for asking questions and receiving answers.
If you want a second perspective that's useful for evaluating vendors and implementation styles, Kogifi's guide to headless platforms is a good reference.
What decoupling changes in practice
This separation isn't just cleaner architecture jargon. It changes how teams build.
Headless commerce architecture decouples the frontend from the backend, enabling independent development cycles that can reduce operational latency by 40-60% in large-scale ecommerce implementations, according to Virto Commerce's overview of the model.
That matters because frontend and backend teams rarely have the same goals on the same day.
| Layer | Main job | What changes faster |
|---|---|---|
| Frontend | Experience, interaction, rendering, device-specific UX | Campaign pages, navigation, layouts, app behavior |
| API layer | Secure data exchange and orchestration | Integration rules, payload design, routing |
| Backend | Commerce logic and core business rules | Catalog, pricing, order processing, account logic |
In a monolith, these concerns are glued together. In a headless model, they can evolve independently.
The architectural win isn't separation for its own sake. It's giving each team permission to optimize its own layer without breaking the others.
That's why headless often shows up in companies that want better app experiences and stronger scalability. A React or Vue storefront can move fast. A mature commerce backend can stay stable. The API contract becomes the agreement that keeps the whole system coherent.
The Building Blocks of a Headless Architecture
Once the concept clicks, the next question is practical. What do you need to run a headless stack well?
The answer isn't “pick a frontend framework and call it done.” Strong headless implementations work because the supporting components are chosen deliberately. The architecture is modular, but it still needs a clear center of gravity around data, APIs, and operational ownership.
The core stack you'll almost always need
At minimum, five layers are assembled.
- Presentation layer: This is your storefront or app experience. Teams often use frameworks like React, Vue, or a server-rendered web stack because they want tighter control over UX, performance, and release cadence.
- Commerce engine: This handles transactional logic. Cart behavior, checkout, promotions, customer accounts, and order management still need a system of record.
- API orchestration layer: This exposes data and capabilities consistently to every frontend touchpoint. It also gives you a place to manage access, transformation, and service composition.
- Content system: A dedicated CMS keeps editorial content out of the commerce engine. That matters when brand teams need flexibility that product catalog structures can't provide.
- Operational data tools: This layer incorporates PIM, search, analytics, and integration services. These tools determine whether your stack feels coherent or stitched together.
Why PIM stops being optional
If I had to name the component teams underestimate most, it's Product Information Management, or PIM.
In a monolithic stack, product data can limp along in messy structures because the same application renders most touchpoints. In a headless system, that breaks quickly. The moment you distribute product content across web, mobile, marketplace feeds, in-store surfaces, or AI-powered experiences, data quality becomes an architectural issue, not a merchandising inconvenience.
A strong PIM gives you a controlled source for titles, attributes, taxonomies, variants, media relationships, and enrichment workflows. It makes your product data API-ready.
According to Plytix's analysis of headless commerce architecture, a robust Product Information Management solution is a critical prerequisite, as its absence can lead to a 50% increase in data inconsistency errors. Successful modular stacks see a 2.5x faster deployment of new customer experiences.
Bad product data will sabotage a headless rollout faster than bad frontend code. APIs only expose the quality of what sits behind them.
Best-of-breed works when ownership is clear
The best headless stacks are rarely built around a single vendor doing everything. They're assembled from tools that each solve a specific problem well.
That sounds ideal until nobody knows who owns cross-system behavior.
Here's the practical tension:
| Component choice | What works | What fails |
|---|---|---|
| Best-of-breed tools | Clear domain boundaries, stronger specialist capability, easier replacement over time | Tool sprawl without governance |
| Single-vendor preference | Faster early setup, simpler procurement, fewer integration points at first | Hidden lock-in and weaker flexibility |
| Custom middleware | Better control over orchestration and business rules | Too much bespoke code with no long-term owner |
The architecture should reflect business priorities. If content velocity drives growth, your CMS and frontend patterns need attention. If complex catalog logic defines the business, invest in PIM and service contracts first. If omnichannel consistency matters, API design discipline becomes a board-level concern, not just an engineering preference.
A modular stack pays off when each component has a reason to exist and a team responsible for it.
Choosing Your Architectural Pattern
Not every company needs the same version of headless. Some need a full strategic rebuild. Others need a controlled way to modernize the customer experience without tearing out the backend.
That's why the pattern matters as much as the technology.

MACH for organizations that need real flexibility
For enterprise teams, MACH has become the clearest architectural north star. The term stands for Microservices-based, API-first, Cloud-native, and Headless. It gained broader legitimacy when the MACH Alliance formed in 2020, which helped establish the model as a modern commerce standard, as noted in the earlier Envive source.
MACH fits companies that need independent services, strong integration discipline, and cloud-native scaling patterns. It's a good match when the business expects multiple channels, complex workflows, and long-term platform evolution.
If your team is still mapping out service boundaries, this microservices architecture example from Wonderment Apps offers a useful way to think through decomposition.
Composable for teams building around capabilities
Composable commerce takes the same spirit and pushes it further. Instead of buying one broad platform, you assemble packaged business capabilities. Search from one vendor. Content from another. Promotions, checkout, analytics, and personalization from others.
That can be the right move if your business gains advantage from picking specialized tools. It's especially attractive when one department's needs are far more advanced than the default capabilities in an all-in-one platform.
But composable doesn't reduce complexity. It redistributes it. Your architecture team becomes the product manager of the platform itself.
Hybrid headless for pragmatic modernization
Hybrid headless is the pattern I recommend most often for teams that need progress without unnecessary trauma.
You keep more of the existing backend in place, then decouple the customer-facing layer where it delivers the biggest upside. That may mean launching a new web experience while leaving checkout or order systems largely intact. It may mean introducing a CMS and API layer before replacing the commerce engine.
Decision lens: Choose the pattern your operating model can support, not the one that sounds most modern in a vendor pitch.
To put it in simple terms:
- Choose MACH when platform flexibility is strategic and your engineering organization can own distributed systems.
- Choose composable when specialized business capabilities justify a more curated stack.
- Choose hybrid headless when you need frontend agility now, but can't justify full replatforming risk yet.
The right pattern is the one your teams can run well for years, not the one that wins architecture diagrams.
Navigating Security and Scalability Concerns
The strongest arguments against headless are often useful ones. More services mean more interfaces. More interfaces mean more security boundaries, more observability work, and more chances to create a messy platform if governance is weak.
That criticism is fair.
A monolith hides a lot of complexity inside one system. Headless exposes complexity and asks you to manage it directly. For mature teams, that's a strength. For under-resourced teams, it can become a problem fast.
Security is now an architectural discipline
In a headless environment, your API layer becomes one of the most important control points in the system. It's where authentication, authorization, rate control, service-to-service trust, and auditability need to be designed intentionally.
That doesn't mean headless is less secure. It means security can't be accidental.
Good implementations usually share the same habits:
- Protect APIs consistently: Every frontend and service should access capabilities through clearly governed interfaces, not ad hoc shortcuts.
- Separate duties: Frontend teams shouldn't own backend secrets, and content editors shouldn't gain unintended access to transactional systems.
- Log decisions, not just errors: Security teams need traceability around who called what, when, and with which permissions.
- Version contracts carefully: Breaking API changes create operational risk just as surely as exposed endpoints do.
Teams looking at the API layer first should also review these API authentication best practices from Wonderment Apps, especially when multiple applications and internal services are involved.
Scalability improves, but operations get sharper edges
The scaling benefit of headless is straightforward. You can scale the customer-facing layer independently from backend commerce services. That's a big advantage when traffic spikes hit browsing harder than checkout, or when mobile usage patterns differ from desktop.
You also gain freedom to optimize each layer differently. Frontend caching, content delivery, asynchronous workflows, and service-level autoscaling become easier to reason about because they're no longer trapped inside one release unit.
But there's a catch. Smaller businesses often hear “omnichannel” and assume headless automatically fits them. It doesn't.
According to Builtt's discussion of headless adoption barriers, a 2025 Forrester report found that 58% of SMBs attempting a headless migration abandoned the project due to the complexity of managing multiple frontend updates concurrently.
Headless rewards teams that can operate distributed systems. It punishes teams that buy flexibility without budgeting for ownership.
That's the key CTO question. Not “Can this scale?” It can. The question is whether your team structure, vendor model, and operational discipline can scale with it.
A Phased Migration and Implementation Checklist
The cleanest headless programs don't start with a replatforming announcement. They start with a narrow business problem and a migration plan that respects operational risk.
Most failures happen because leadership tries to replace everything at once. That creates too many dependencies, too much uncertainty, and no safe rollback path.
The better pattern is phased delivery. Keep the business running, decouple deliberately, and replace pieces in an order your teams can support.

Six phases that keep risk under control
Strategy and discovery
Start with business goals, not platform preferences. Are you trying to speed up launches, improve app performance, unify channels, support international merchandising, or prepare for AI features? Audit the current stack with those outcomes in mind.Architectural design
Define domain boundaries early. Decide what remains system-of-record for products, pricing, orders, customers, and content. Write API contracts before teams build around assumptions.Backend decoupling
This doesn't always mean replacing the commerce platform immediately. Sometimes it means exposing cleaner services around what already exists. Sometimes it means introducing middleware to reduce direct coupling.
What leaders should ask before build begins
A migration checklist is only useful if it forces the right questions.
- Who owns the data model: If catalog, content, and customer data have overlapping ownership, the architecture will mirror that confusion.
- Which experience moves first: Homepage rebuilds are visible, but account flows, search, or product detail pages may produce better learning.
- How will you test across touchpoints: Headless creates freedom, but it also multiplies integration paths.
- Which partners can operate the stack after launch: A flashy build with no sustainable support model is just deferred risk.
Start with the customer journey that hurts the business most, not the one that makes the architecture deck look the cleanest.
The implementation habits that actually help
The migration pattern I trust most is close to the strangler fig approach. Introduce new capabilities around the edges. Route selected traffic or workflows through the new architecture. Retire old paths as confidence grows.
A practical checklist for launch readiness looks like this:
| Checkpoint | What good looks like |
|---|---|
| API readiness | Contracts are documented, stable, and understood by frontend and backend teams |
| Data readiness | Product and content sources are clean enough to serve multiple channels |
| Operational readiness | Monitoring, alerting, and ownership are defined before go-live |
| Editorial readiness | Business users can update content and merchandising without engineering bottlenecks |
| Rollback readiness | The team knows exactly how to isolate or reverse a failing release |
Phased migrations feel slower at first. In practice, they usually deliver faster because the business doesn't spend months waiting for a perfect cutover that never arrives.
Building for the Future with AI and Smart Tooling
A headless stack is valuable on its own, but its bigger role is what it enables next.
AI in commerce works best when data is structured, systems are modular, and interfaces are available through stable APIs. That's why companies modernizing for personalization, search, service automation, or internal productivity often end up modernizing architecture first. The AI layer needs clean access to product context, customer signals, business rules, and content assets. A rigid monolith makes that harder than it should be.
Why AI fits naturally on top of headless
When the frontend is decoupled and the backend exposes clear services, teams can add intelligence where it matters.
That might mean AI-assisted product discovery in the storefront. It might mean recommendation logic tied to catalog attributes and customer behavior. It might mean internal tools for merchandising teams, support teams, or content teams that need faster workflows without direct database access.
For a broader look at where AI creates practical value in digital retail, this overview of AI in ecommerce from Wonderment Apps is worth reading.
The important architectural point is simple. AI features shouldn't be bolted into random corners of the stack. They should sit on top of well-defined services and controlled data pathways.
The operational problem most teams discover late
Adding AI creates a new management surface. Prompts evolve. Parameters change. Logging requirements grow. Costs need tracking. Sensitive internal context needs access control. None of that is handled well when prompts live half in source code, half in spreadsheets, and half in someone's notes from a workshop.
That's where many otherwise experienced teams lose control. They build the feature but not the administration around the feature.
The missing layer is usually an internal control plane for AI operations. In practice, that means capabilities such as:
- Prompt vault with versioning: Teams need to know which prompt is active, what changed, and why output quality shifted.
- Parameter management for internal data access: AI workflows need governed ways to pull the right context from internal systems without turning every integration into a security exception.
- Centralized logging across integrated models: Product, engineering, and compliance teams need visibility into how AI behaves across apps and environments.
- Cost management: Leaders need a clear view of cumulative AI spend before experimentation turns into billing surprise.
The future-proof stack isn't just headless. It's headless plus disciplined AI operations.
What lasts and what turns into technical debt
The companies that build durable intelligent commerce platforms usually follow the same pattern. They separate presentation from transaction logic, structure their data, define clean APIs, and treat AI as an operational capability that needs governance from day one.
What doesn't last is the shortcut version. One-off chatbot integrations. Hard-coded prompts buried in repositories. Unowned model settings. No usage tracing. No spend visibility. No reliable handoff between product ideas and production systems.
Headless commerce architecture gives you the foundation. Smart tooling determines whether the intelligence you add on top remains manageable six months later.
If you're modernizing a commerce platform and want help building the architecture, delivery team, and AI operations layer together, Wonderment Apps is a strong partner to evaluate. Their team works across web, mobile, AI modernization, and scalable product delivery, and they've developed an administrative prompt management system with a prompt vault, versioning, parameter controls for internal database access, centralized logging across integrated AIs, and cost management visibility. If you want to see how that tooling fits into a real modernization roadmap, schedule a demo with Wonderment Apps.