
Your analytics stack probably works fine for yesterday's questions. Revenue by channel, weekly cohort retention, margin by product line. Then the roadmap shifts. Product wants AI search. Marketing wants real-time personalization. Risk wants anomaly detection. Suddenly the data foundation that made BI easy starts slowing everything down.
That's the core decision behind data lakehouse vs data warehouse. It isn't a branding debate. It's a decision about whether your core platform can support both structured reporting and the messy operational data that modern applications generate. It's also a governance decision, because once AI features enter your mobile app, web platform, or internal admin tools, you need tighter control over prompts, parameters, logging, and model spend, not just cleaner dashboards.
For CTOs in ecommerce, fintech, and healthcare, this choice usually shows up when teams are tired of moving data between too many systems. You've got one platform for reports, another for raw logs, another for ML experiments, and a growing list of integrations glued together with fragile pipelines. That complexity doesn't stay in the data team. It leaks into delivery speed, app performance, security reviews, and the cost of every new feature.
The Modern Data Dilemma Lakehouse vs Warehouse
The old pattern is familiar. Your warehouse powers finance reports and executive dashboards. It's stable, predictable, and good at answering known business questions. Then your product team asks for recommendations based on clickstreams, support transcripts, images, or application logs. That's where the friction starts.
Data warehouses have dominated analytics since the 1970s, but the game changed around 2020 with the rise of the data lakehouse. Today, over 60% of large enterprises are implementing lakehouse architectures to handle the 80% of their data that is unstructured, a necessity for modern AI.
Why leaders hit this wall
The issue usually isn't that the warehouse is “bad.” It's that it was built for a narrower job.
- Reporting was the first priority: Warehouses were designed to serve BI, consistent metrics, and SQL-first analysis.
- AI changes the data mix: Recommendation engines, fraud models, document extraction, and operational copilots depend on logs, text, event streams, images, and other formats that don't fit neatly into rigid warehouse pipelines.
- Integration burden grows fast: Every time teams copy or reshape data for another tool, they create more maintenance work and more places where governance can fail.
Practical rule: If your data platform requires separate copies of the same data for BI, ML, and near real-time use cases, architecture is already becoming a delivery bottleneck.
For software leaders, this isn't just about storage. It affects how fast you can ship product improvements across desktop and mobile apps, how safely you can expose AI to customers, and whether your engineering team can support scale without building a maze.
Two architectures, two operating models
A warehouse says: define structure first, then load data into a highly optimized analytics system.
A lakehouse says: keep the flexibility of low-cost object storage, but add enough transactional and management capability to support serious analytics and AI on the same platform.
That difference changes how teams design software. Warehouses tend to favor curated, known workflows. Lakehouses tend to favor broader ingestion, later modeling, and more experimentation. Neither approach wins by default. The right choice depends on the shape of your data, the speed your product roadmap demands, and whether AI is a side project or a core capability.
What Are Data Warehouses and Lakehouses
A data warehouse is a centralized analytics system for cleaned, structured data. It uses schema-on-write, which means teams define the data model before ingestion. That discipline is useful when finance, operations, and BI teams need consistent reporting and tightly governed datasets.
A data lakehouse is a hybrid architecture. It combines low-cost object storage with warehouse-style capabilities such as transactional reliability and analytical performance. It supports structured, semi-structured, and unstructured data in native formats, which makes it a better fit for teams that need one platform for SQL analytics, data science, and AI work.
The schema difference matters more than most teams expect
The biggest practical difference is schema handling. Data warehouses enforce schema-on-write, which can break when data formats change. Lakehouses use schema-on-read with open formats like Delta Lake or Iceberg, unifying BI and ML workloads on a single, flexible data copy (Panther's comparison of warehouse, lake, and lakehouse patterns).
In real systems, that means a warehouse asks your team to prepare data before it enters the platform. A lakehouse lets you land more data earlier and apply structure later, when you know how the business wants to use it.
If you want a solid refresher on classic modeling principles, TekRecruiter's data warehouse design guide is a practical primer. For a simpler conceptual walkthrough, Wonderment's overview of the data warehousing concept is also useful for non-specialist stakeholders.
What each architecture is best at
Here's the short version.
- Choose a warehouse when your core need is stable BI, structured reporting, and governed SQL analytics on curated datasets.
- Choose a lakehouse when your roadmap includes AI, mixed data types, streaming data, or model training on raw operational data.
- Use caution when your team assumes a lakehouse is just a cheaper warehouse. It isn't. It changes data operations, governance patterns, and engineering responsibilities.
A warehouse feels like a well-run archive. A lakehouse feels like a platform for active product development.
That distinction matters if you're modernizing legacy software. In app development, the data layer determines what features are even feasible. If your architecture can't support raw events, logs, documents, and behavioral data without heavy preprocessing, your AI roadmap will move slower than your competitors'.
Warehouse vs Lakehouse A Detailed Comparison
A CTO choosing between a warehouse and a lakehouse is rarely choosing between two database products. The choice is operating model. One favors tightly curated analytics with strong predictability. The other favors a broader data platform that can support BI, data science, and AI work from the same foundation.
Data Warehouse vs. Data Lakehouse At a Glance
| Criterion | Data Warehouse | Data Lakehouse |
|---|---|---|
| Primary data type | Structured data | Structured, semi-structured, and unstructured data |
| Schema approach | Schema-on-write | Schema-on-read |
| Best fit | BI dashboards, reporting, governed SQL analytics | Unified BI, AI/ML, data science, and mixed workloads |
| Storage model | Specialized warehouse storage | Low-cost object storage with a transactional layer |
| Streaming support | Primarily batch-oriented | Handles batch and streaming data |
| AI readiness | Requires transformation into warehouse-compatible formats | Supports model training directly on raw data |
| Flexibility | High performance, lower flexibility | Broad flexibility across evolving use cases |
| Operational profile | Mature and predictable for traditional analytics | More adaptable, but often more complex to manage |
Where warehouses still win
Warehouses remain the safer choice for stable, high-trust reporting. If the business runs on finance dashboards, board packs, regulatory metrics, or tightly governed SQL access, a warehouse gives teams fewer moving parts and clearer performance behavior.
That matters in fintech and healthcare. Auditability, role-based access, and repeatable metric definitions often carry more weight than broad format support. In these environments, strong structure reduces operational risk.
Warehouses also fit organizations where the analyst population is much larger than the data engineering team. If nearly every important workload is already modeled, structured, and queried through SQL, the warehouse model stays efficient.
Where lakehouses pull ahead
Lakehouses solve a different problem. They let teams keep raw operational data, event streams, documents, and machine-generated data in one platform, then apply structure as use cases mature. For ecommerce, that can mean clickstream, search behavior, product catalog changes, support transcripts, and order events living in the same system. For healthcare, it can include claims data, notes, device feeds, and logs. For fintech, it often means transaction events, fraud signals, API telemetry, and model features.
The key technical shift is that modern lakehouses add table management and transactional behavior on top of object storage. That makes update, delete, versioning, and schema evolution practical without forcing every dataset into warehouse storage on day one.
AI strategy changes the comparison quickly. A warehouse can support AI, but usually through extra pipelines, feature extraction steps, and duplicated storage. A lakehouse tends to fit AI work better because data scientists and ML teams can work closer to source data instead of waiting for every input to be remodeled first.
The hidden trade-off is operational complexity
Lakehouses are flexible, but they ask more from the platform team. File layout, partitioning, table maintenance, metadata quality, orchestration, and workload isolation all matter. A weak operating model can turn a promising lakehouse into a slow and confusing data estate.
That is why architecture decisions should be tied to team maturity, not just product ambition.
If your engineers already run distributed processing or event-heavy pipelines, the transition is more manageable. If you need a practical refresher on the underlying processing stack, Wonderment's explanation of Spark and Hadoop architecture trade-offs is useful context.
How the choice plays out in practice
A warehouse is usually the better fit when the business asks for consistency first. The lakehouse is usually the better fit when the business needs optionality.
Use that distinction as a decision test:
- Choose a warehouse if your highest-value workloads are structured, repeatable, SQL-driven, and tightly governed.
- Choose a lakehouse if your roadmap depends on mixed data types, long-term raw data retention, streaming inputs, or AI development.
- Choose carefully if you expect one platform to serve both regulated reporting and experimental product analytics. The architecture can do it, but the operating model has to be designed for both.
I have seen teams get this wrong in both directions. Some force AI and event data into a warehouse-only design, then build side systems a year later. Others adopt a lakehouse for flexibility, then underinvest in governance and data contracts, which creates trust problems for BI users.
What experienced teams watch for
A few mistakes show up repeatedly:
- Treating a lakehouse as a cheaper warehouse: Cost can improve, but only if the team manages storage layout, compute usage, and lifecycle policies well.
- Assuming warehouse performance settles the whole decision: Fast SQL matters, but it does not answer how you will retain raw data, support ML features, or control duplication across tools.
- Ignoring compliance design: In healthcare and fintech, masking, lineage, retention, and access policies need to be built into the architecture from the start.
- Optimizing for current reporting only: That choice often slows future product analytics, personalization, anomaly detection, and AI use cases.
The right architecture is the one that fits your revenue model, compliance burden, and data team maturity, not the one with the cleanest vendor pitch.
Analyzing Performance and Total Cost of Ownership
A CTO choosing between a lakehouse and a warehouse is rarely buying query speed alone. A key decision is whether the platform will still make financial and operational sense once raw retention, AI workloads, governance, and team overhead show up in year two.
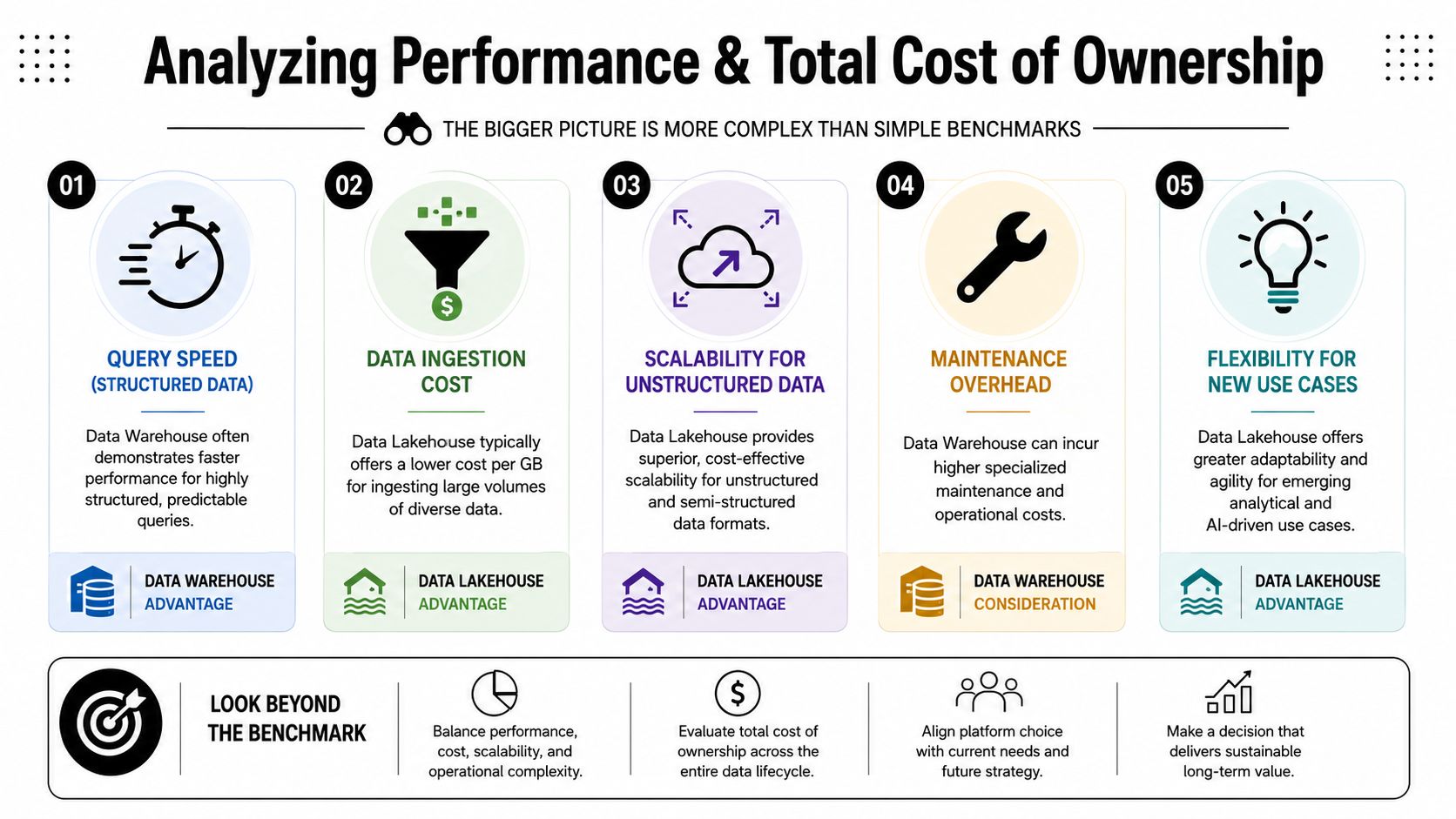
Raw speed versus platform economics
Benchmarks still matter. In one Microsoft Fabric Capacity test, a Data Warehouse completed operations on a 3 billion record dataset in 8 minutes, about 50% faster than a Lakehouse, but at a much higher cost in Compute Units (SQLReitse benchmark write-up).
That result lines up with what many teams see in practice. Warehouses usually win on tightly modeled, structured analytics with predictable SQL patterns. If your business runs on finance reporting, executive dashboards, and strict SLAs for BI, that performance can justify the spend.
The mistake is treating that benchmark as a full TCO model.
Storage economics change the decision
Storage strategy has a bigger effect on long-term cost than many architecture decks admit, especially in ecommerce, fintech, and healthcare. Those teams often need to keep high-volume raw data for auditability, feature engineering, model retraining, and future use cases they cannot define yet.
Amazon Redshift and Google BigQuery can cost 3–5 times more per terabyte than S3 or ADLS object storage used for data lakes, which makes keeping raw, high-volume data in warehouse storage far less attractive (discussion of warehouse versus object storage economics).
That is why warehouse-first programs often end up with two stacks. Raw data stays in object storage because the economics are better. Curated tables move into the warehouse for BI performance. Then the team inherits duplicate pipelines, duplicate governance work, and recurring debates about which copy of the data is current.
If your environment already has that split, a plan grounded in database migration best practices helps reduce cutover risk and prevents one expensive platform from becoming two.
Hidden operating costs are usually people costs
Lakehouses can lower storage cost and reduce data duplication, but they do not remove engineering work. They shift where the work happens. Teams still need to manage table formats, metadata, partitioning, access controls, quality checks, and lifecycle policies. If that discipline is weak, a low-cost storage layer turns into an expensive trust problem for analysts and product teams.
I have seen this play out in mid-market companies that adopted a lakehouse for flexibility before they had strong platform ownership. Infrastructure spend looked good. Delivery speed did not. Analysts waited on engineering for fixes, data contracts stayed informal, and governance became reactive.
That is why total cost of ownership should include four buckets:
- compute and storage
- pipeline and platform maintenance
- governance, compliance, and audit effort
- the cost of delay when teams cannot find or trust data
For AI-readiness, that last category matters more than many budget models reflect. A warehouse can look cheaper if you price only reporting workloads. A lakehouse can look cheaper if you ignore platform discipline. The better question is which architecture fits your mix of BI, raw retention, ML, compliance, and staffing capacity over the next three years.
Lakehouse vs Warehouse in Action Use Cases
A retailer wants same-session product recommendations before peak season. A fraud team wants to stop suspicious transactions before authorization clears. A hospital wants clean regulatory reporting while preparing to use imaging and clinical notes for AI. Those are not the same problem, and they should not default to the same architecture.
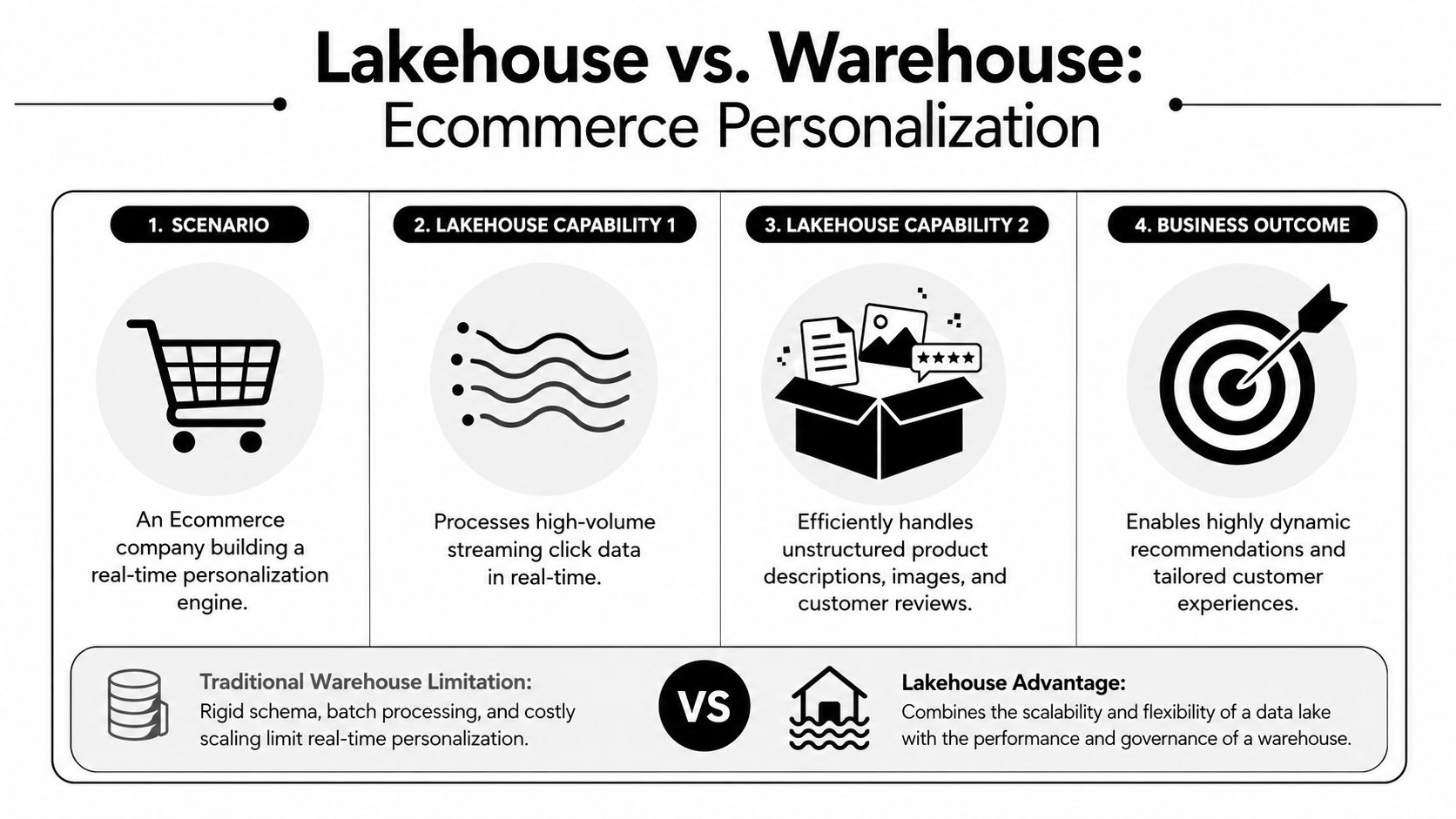
Ecommerce and fintech
Ecommerce teams usually hit the limit of a warehouse when personalization becomes a revenue priority. Dashboards and merchandising reports still run well on structured tables, but recommendation systems need more than orders and customer profiles. They pull from clickstream events, search behavior, inventory changes, reviews, and sometimes product images or text. A lakehouse is often the better fit when those workloads need to share data with BI and ML teams without copying everything into separate systems.
Fintech has a similar pattern, but the tolerance for delay is lower. Fraud models work better when they can use transaction history alongside device signals, login events, API activity, and behavioral anomalies. A warehouse can support investigation, reporting, and governed financial metrics. It becomes less attractive when every new detection feature requires another transformation path and another delay between raw ingestion and model use.
The practical question is not whether a lakehouse can store more types of data. It is whether the business value depends on using that data fast enough to affect the customer or the transaction.
Healthcare and media
Healthcare leaders usually need both control and flexibility. For claims analytics, quality reporting, and finance, a warehouse remains a strong option because the metrics are defined, audited, and repeatedly used. For imaging, physician notes, research datasets, and longitudinal patient data, the architecture has to handle files and semi-structured content that do not fit neatly into warehouse-first models.
That split matters for AI readiness. If the near-term goal is regulated reporting, a warehouse may be enough. If the roadmap includes clinical summarization, risk scoring, document extraction, or research collaboration, a lakehouse often becomes the staging ground for those inputs.
Media companies tend to reach that point earlier. Viewer events, session logs, search activity, ad performance, and content metadata arrive continuously and change quickly. Teams building content recommendations or live audience operations usually benefit from a lakehouse because they need one platform that can retain raw behavior data and still serve downstream analytics.
Public sector and hybrid realities
Public sector teams rarely get to choose a clean slate. They inherit reporting obligations, legacy systems, document repositories, geospatial data, and public data publishing requirements at the same time. In that environment, a warehouse still fits standardized reporting and budget analysis. Lakehouse patterns fit broader data access needs, especially where agencies need to work with files, maps, archives, sensor feeds, or open datasets.
Hybrid is common for a reason. Many organizations are not choosing between warehouse or lakehouse in one step. They are deciding where the system of record for analytics should live, which workloads need raw and varied data, and which data products justify tighter warehouse controls.
Use cases usually break down like this:
- Warehouse-first: board reporting, finance, standardized healthcare reporting, stable KPI tracking, and heavily modeled business data
- Lakehouse-first: personalization, fraud detection, content recommendations, document and image analysis, research data, and operational AI
- Hybrid: enterprises with mature BI requirements, strict governance needs, and an active roadmap for ML or generative AI
The right choice follows the product and compliance demands. If the business wins by answering known questions with high consistency, start with a warehouse. If it wins by combining varied data quickly enough to power models and automation, start with a lakehouse or plan for a hybrid design early.
How to Choose Your Data Architecture
A CTO usually reaches this decision under pressure. The board wants cleaner reporting. Product wants real-time signals. The AI team wants access to raw events, documents, and conversation data without waiting six months for a new modeling layer.
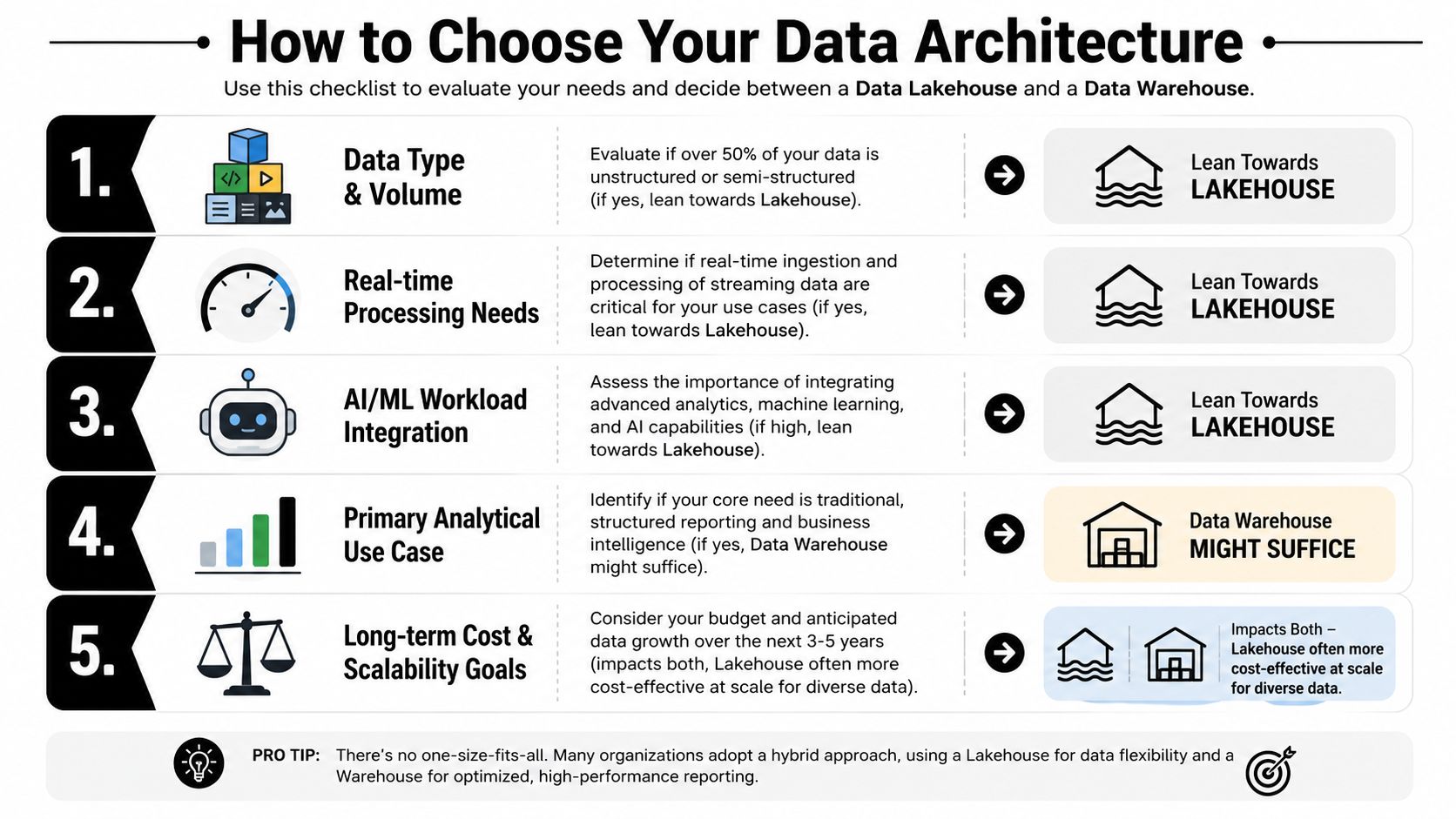
The right answer comes from operational fit, not architecture fashion. In practice, the choice depends on how much data variety you need to support, how disciplined your governance model is, what your team can run reliably, and whether AI will stay experimental or become part of the product and decision flow.
Five questions that lead to the right call
What data will matter in two years, not just this quarter?
If the core of the business is structured transactions, curated dimensions, and stable metrics, a warehouse is usually the lower-risk choice. If the roadmap includes clickstream data, support transcripts, device events, images, PDFs, or model training data, a lakehouse becomes much more attractive.Which workload pays the bills?
Warehouses are still strong for finance reporting, executive dashboards, and governed SQL analysis. Lakehouses fit teams that need one platform for analytics, data science, feature generation, and large-scale ingestion.Where will operational complexity sit?
A warehouse often hides more of the infrastructure burden. A lakehouse gives more flexibility, but the team has to handle file layout, table formats, metadata quality, access patterns, and performance tuning with more care.How expensive is duplication in your current stack?
If analysts, engineers, and ML teams are all copying the same data into different systems, the architecture is already costing more than the platform bill suggests. A lakehouse can reduce some of that duplication. A warehouse can still be the better choice if consistency and controlled semantics matter more than broad data access.What does AI-readiness require in your industry?
Ecommerce teams often need behavioral data, product content, and fast experimentation. Fintech teams usually need lineage, policy controls, and low tolerance for ambiguous metrics. Healthcare leaders need to balance governed reporting with document-heavy and multimodal data. For retail leaders assessing how customer, transaction, and behavioral data come together, this overview of big data in retailing adds useful business context.
A practical decision lens for CTOs
Use a warehouse when the business depends on standardized reporting, certified metrics, and predictable query performance for a broad analyst base.
Use a lakehouse when future value depends on combining structured and unstructured data, supporting AI workflows, and avoiding constant data movement between analytics and ML environments.
Choose a phased approach when the destination is clear but the team is not ready to run a lakehouse well on day one. That usually means keeping reporting on the warehouse while building new AI and high-variety workloads on lakehouse foundations.
The best architecture is the one that fits your operating model now and does not force a second platform rewrite when AI moves from pilot to production.
Unlocking AI with Modern Data and Prompt Management
A strong architecture is only the base layer. Once teams start embedding AI into customer-facing apps, internal workflows, and business operations, a second problem appears. Managing how models are used becomes as important as managing the data they read.
The teams that do this well don't treat prompts as scattered strings hidden in application code. They manage them as operational assets. That means versioning prompt changes, controlling model parameters, logging AI activity across integrations, and tracking cost before usage drifts.
This becomes especially important in sectors like retail, where data variety and decision speed shape customer experience. If you want a wider business lens on that shift, this piece on big data in retailing is a useful complement to the architecture discussion.
For companies modernizing legacy software, an administrative control layer is often the difference between an AI feature that demos well and one that can survive production. The useful pattern is straightforward:
- Keep prompts governed: Store and version them centrally.
- Control data access carefully: Manage parameters for internal database access instead of hard-wiring risky shortcuts.
- Log across AI integrations: Create a unified record of what each model did and when.
- Track cumulative spend: Cost visibility matters once multiple models and environments enter the mix.
That's the operational side of AI modernization. The data platform decides what your apps can learn from. Prompt and integration management decides whether those apps stay reliable, governable, and cost-aware as usage grows.
If you're modernizing an app for AI, Wonderment Apps can help you bridge both layers: the product engineering needed to upgrade web and mobile software, and the administrative tooling needed to manage prompts, parameters, logging, and cumulative model spend. If you want to see how that works in a real application environment, request a demo.