
Let's be honest, building a scalable web application isn't just another item on a technical to-do list anymore. It's the very foundation of a modern business strategy. We're talking about designing systems that can gracefully handle a surprise feature on the news, massive spikes in data, and new feature rollouts—all without crashing, grinding to a halt, or forcing you back to the drawing board. A key part of modernizing your app for the future is preparing it for AI integration, and that requires specific tools to manage the complexity. For instance, a smart prompt management system can be plugged into your existing software to help you manage AI features without getting bogged down.
Why a Scalable Architecture is Your Secret Weapon
Scalability has shifted from a nice-to-have to your primary competitive moat. It's the new standard. For any business in ecommerce, fintech, or SaaS, the ability to grow without friction is non-negotiable. An application that buckles under its own success is a huge liability, leading directly to lost customers and a damaged reputation.
Building for scale means creating a resilient foundation that can actually support your ambition. When your big break comes, you need to know your technology is ready for it.
The economics of this shift are staggering. The global web application market is on track to hit about $167.1 billion by 2030, a surge driven by the very cloud-native and microservices architectures that make scaling practical. With over 92% of enterprises planning to modernize or build new cloud-native apps, the message is clear: scale or get left behind. You can dig deeper into the evolution of web application development to see how these trends are reshaping the industry.
Before we dive into the "how," it's crucial to understand the fundamental components that make a scalable architecture work. These are the pillars you'll build upon.
Core Pillars Of Modern Scalable Architecture
| Pillar | What It Is | Why It Matters For Scale |
|---|---|---|
| Decoupling | Breaking down a large application into smaller, independent services (like microservices). | Prevents a single failure from taking down the entire system. Allows teams to work on and deploy services independently. |
| Elasticity | The ability to automatically add or remove resources (servers, containers) based on real-time demand. | Ensures you have exactly the resources you need—no more, no less. Handles traffic spikes without manual intervention. |
| Resilience | Designing the system to withstand failures by building in redundancy and failover mechanisms. | Minimizes downtime and maintains a positive user experience, even when individual components fail. |
| Observability | Gaining deep insights into your system's performance through logs, metrics, and traces. | Helps you quickly identify bottlenecks, troubleshoot issues, and understand how your application behaves under load. |
These pillars aren't just abstract concepts; they are the strategic principles that guide every decision you'll make, from choosing a database to setting up your deployment pipeline.
Thinking Beyond Just Adding Servers
True scalability requires a fundamental shift in how you approach design, development, and operations. It’s less about brute force and more about building a system composed of independent, resilient parts that work together in harmony.
This guide will unpack the core concepts that make this a reality:
- Architectural Patterns: We'll explore the blueprints, from microservices to serverless, that are designed to eliminate single points of failure.
- Intelligent Operations: We’ll look at how integrating AI can create smarter, self-healing systems that adapt to demand automatically.
- Modern Tooling: We will show you how to create smarter, more resilient systems that grow right alongside your business.
Modernizing for an AI-Powered Future
Bringing AI into the mix is a powerful way to modernize, but it’s not without its challenges. Suddenly you're juggling different AI models, prompts, costs, and versions. A well-designed scalable architecture has to account for these new, complex demands.
The real challenge isn't just handling more traffic; it’s about creating intelligent, adaptable systems. This is where modernizing your application with smart administrative tools, like a prompt management system for AI integrations, becomes essential for building applications designed to last and scale effectively.
This is where a tool like Wonderment's prompt manager becomes the central nervous system for your AI features. It gives you a single place to manage, version, and deploy AI prompts with confidence. It’s a critical piece of the puzzle for building scalable web applications that are not only robust but truly intelligent.
Designing Your Architectural Blueprint For Growth
Before you write a single line of code, your architectural choices are already setting the stage for future success or failure. Getting this blueprint right isn't just a technical exercise; it's the strategic decision that separates an app that can handle a million users from one that crashes after a thousand. It’s the difference between smooth, predictable growth and painful, expensive rewrites down the road.
An effective architecture is all about creating a system of independent, communicating parts. Think of it like building a city. Instead of one giant, monolithic skyscraper where a fire on the first floor takes down the whole building, you build a city of interconnected but separate structures. If the post office has a problem, the hospital and the power plant keep running without a hitch. That’s the core idea.
This very decision is what the chart below visualizes—the fork in the road between planning for scale and getting buried in technical debt.
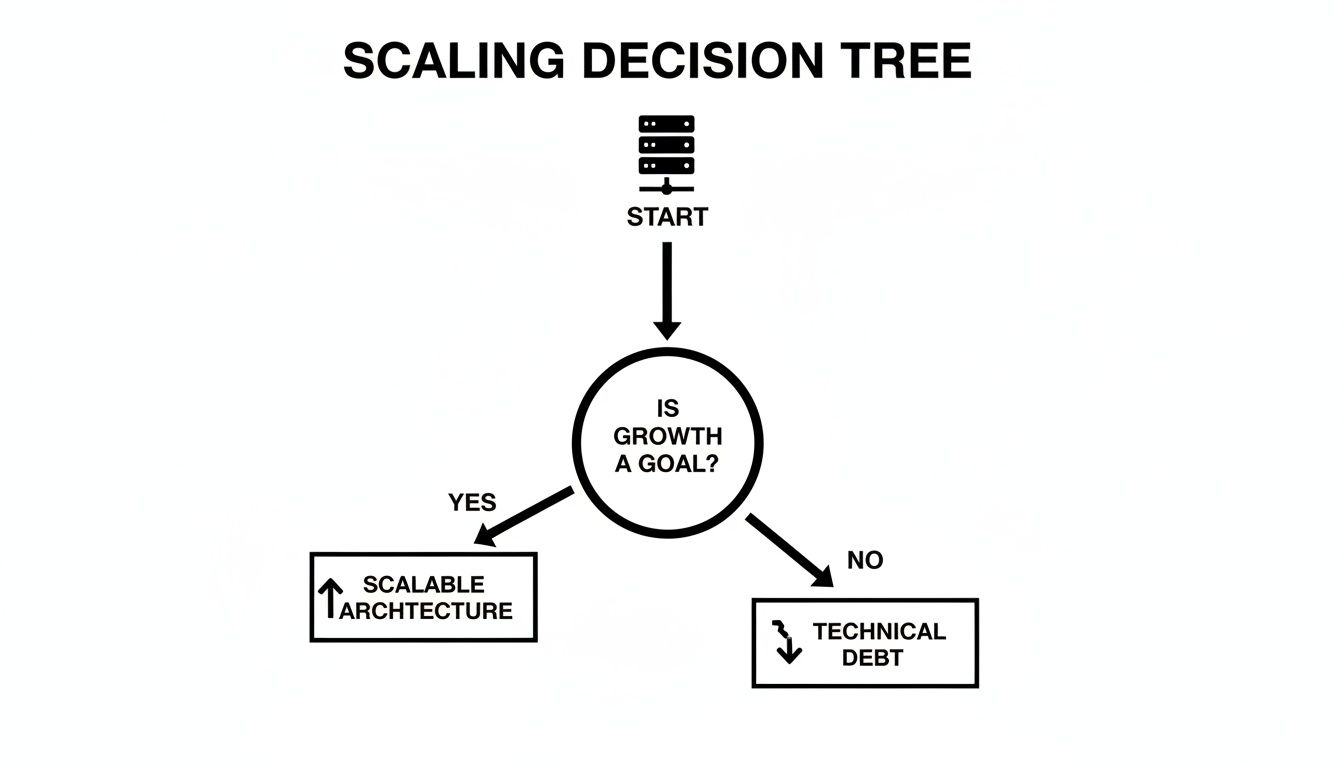
It really boils down to this: if you have any ambition for growth, a scalable architecture is non-negotiable. Kicking that can down the road just builds up technical debt that will eventually cripple your progress.
Choosing Your Architectural Style
The debate over monolithic, microservices, and serverless architectures is always lively, but honestly, the "right" choice depends entirely on your specific needs. Each approach comes with its own set of trade-offs in complexity, operational overhead, and scalability.
- Monolithic: This is the traditional all-in-one approach. The entire application is a single, unified unit. It's often simpler to get off the ground but can become a nightmare to scale or update as it grows.
- Microservices: This style breaks your application into a collection of small, independent services. Each one handles a specific business function, meaning it can be developed, deployed, and scaled on its own.
- Serverless: An event-driven model where you run code without ever thinking about servers. It’s perfect for workloads with unpredictable traffic, since it scales automatically and you only pay for what you actually use.
A common mistake I see is over-engineering from day one. A well-organized monolith can be the perfect choice for an early-stage product. The trick is to design it with clear internal boundaries so you can gracefully break it apart into microservices later, once the need for independent scaling becomes real.
The Power of Stateless Services and APIs
One of the golden rules of building scalable web applications is to design stateless services. This simply means that every request from a user is treated as a brand new interaction, with no reliance on data stored from a previous request on that specific server. When you build this way, you can add or remove servers effortlessly to handle traffic spikes.
This whole approach is held together by a robust, API-first design. As you map out your architecture, adopting strong API development best practices is critical. Your APIs become the contracts that allow all your independent services—whether it's user authentication, payment processing, or inventory management—to talk to each other reliably. We explore these principles in more detail in our guide to software architecture best practices.
This decoupled strategy is where the industry is heading. Modern scalable apps are increasingly defined by trends like microservices and AI-assisted development. We've seen microservice adoption in some modern stacks exceed 60%, a major shift away from old-school monoliths. At the same time, surveys show that 77% of developers now use AI coding tools, with nearly 90% of engineering teams incorporating AI somewhere in their development lifecycle. Embracing these patterns helps you build a foundation that isn't just ready for today's traffic but is prepared for whatever tomorrow throws at it.
Choosing The Right Tech Stack And Infrastructure
If your architecture is the blueprint, then your technology stack and infrastructure are the steel beams and concrete that bring your application to life. Getting these choices right is what separates an application that thrives under pressure from one that crumbles at the first sign of growth. This isn't about chasing the latest trends; it's about making deliberate, informed decisions to build a high-performance foundation that’s also cost-effective.
Today, the cloud is the default playground for building anything scalable, and for good reason. Providers like AWS, Azure, and Google Cloud offer an incredible toolkit of services specifically designed to handle dynamic, unpredictable workloads. In 2024, AWS still leads the pack with 30% of the cloud market, followed by Azure at 21% and Google Cloud at 12%. Their dominance is a testament to the robust, elastic infrastructure they provide.
These platforms fundamentally change the game. You're no longer in the business of buying, racking, and managing physical servers. Instead, you can spin up the exact resources you need, right when you need them, all through code. This single shift is the absolute key to unlocking both elite performance and financial sanity.
Core Infrastructure Components For Scale
To build an infrastructure that can truly breathe with your user demand, a few technologies are simply non-negotiable. These are the tools that let your application automatically adapt without someone needing to manually intervene at 3 AM.
- Autoscaling Groups: This is a foundational concept for elasticity. Instead of guessing how many servers you need, you define rules that automatically add or remove them based on real-time metrics like CPU load or request count. This ensures you always have just enough horsepower—never too little, never too much.
- Containers (Docker & Kubernetes): Containers, usually with Docker, solve the "it worked on my machine" problem by packaging your code and all its dependencies into a single, portable unit. But it’s Kubernetes that really makes them shine at scale. K8s is the conductor of your container orchestra, handling deployment, self-healing, and scaling so you don't have to.
- Serverless Functions (Lambda, Azure Functions): For specific, event-driven jobs, serverless is a game-changer. You upload a piece of code—a function—and the cloud provider handles everything else. It scales from zero to massive and back down again, and you only pay for the precise milliseconds your code is running. It's an incredibly powerful and cost-effective tool for the right kind of workload.
These are your primary building blocks. Of course, how you wire them up to your data layer is just as critical. For a deeper look at how these pieces fit together in a modern distributed system, our guide on microservices architecture best practices is a great next step.
Selecting Your Database And Caching Strategy
Your database can quickly turn from a trusted asset into your biggest bottleneck if you're not careful. The old SQL vs. NoSQL debate is mostly settled now; the reality is that most large-scale apps need both, playing to their respective strengths.
SQL databases like PostgreSQL or MySQL are the gold standard for structured, relational data where consistency is king. Think user accounts, product catalogs, or financial records. You can absolutely scale them effectively using proven patterns like read replicas to offload queries and sharding to horizontally partition your data across multiple instances.
NoSQL databases, on the other hand, such as MongoDB or DynamoDB, are built for speed and horizontal scale with less structured data. They're perfect for things like user session stores, real-time analytics, or massive datasets where the schema might evolve.
The most powerful approach is often a hybrid one. Use a rock-solid relational database for your core, transactional data, and complement it with a NoSQL database for workloads that demand extreme scale or schema flexibility. Trying to force one tool to do every job is a recipe for pain.
Beyond the database itself, caching is your secret weapon for incredible performance. An in-memory store like Redis can hold frequently accessed data, shielding your primary database from repetitive queries and making your app feel lightning-fast.
Finally, for any application with a global audience, a Content Delivery Network (CDN) isn't optional—it's essential. A CDN caches your static files (images, CSS, JavaScript) in data centers all over the world. This means a user in Tokyo gets the same snappy experience as a user in New York because the assets are served from a server right around the corner.
Mastering Data Performance And Reliability At Scale
When your app starts to take off, your data strategy quickly becomes its performance backbone. What worked flawlessly for a thousand users can grind to a halt under the pressure of a hundred thousand. The secret to mastering data at scale isn't some magic bullet; it's about layering smart, proven strategies that work together to build a system that’s both fast and tough.
This means you have to stop thinking of your data layer as a simple storage bucket. It's a dynamic, distributed system. The goal is to hunt down and eliminate bottlenecks, guarantee high availability, and deliver a consistently snappy experience for every user, no matter where they are or how hammered the application gets.
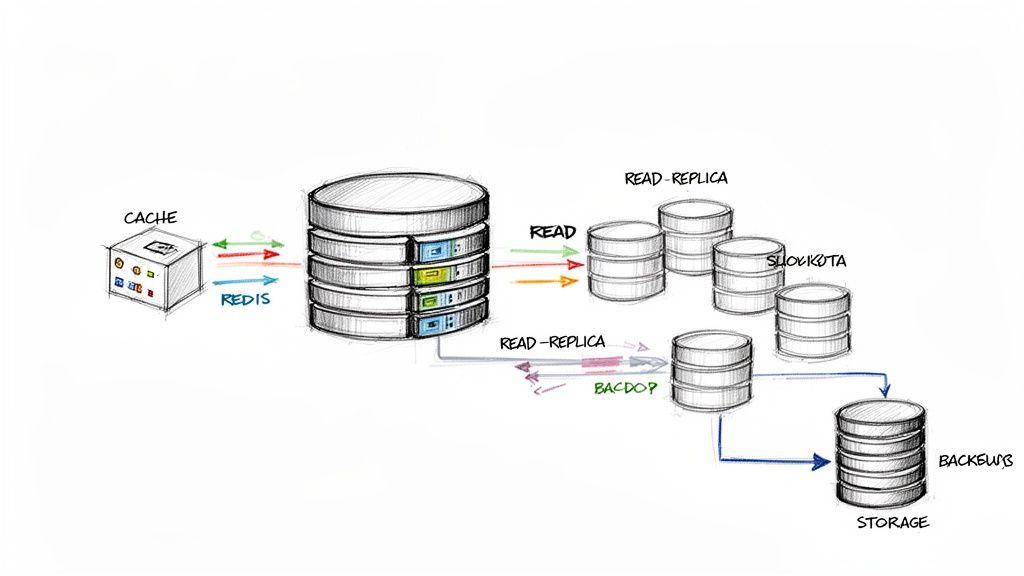
Unpacking Database Scaling Techniques
Once your primary database starts showing signs of strain, you have a few powerful techniques to spread the load. These aren't just for massive, enterprise-level apps—they are practical, essential steps for any growing application.
- Replication and Read Replicas: This is usually the first, and often most effective, move you can make. You simply create one or more read-only copies (replicas) of your primary database. All write operations (like inserts, updates, and deletes) are directed to the primary, while all read operations (select queries) are spread out across the replicas. This one change can dramatically slash the load on your main database.
- Database Sharding: When even read replicas aren't cutting it anymore, sharding is the next logical step. Sharding means you horizontally partition your data across multiple, separate databases. For instance, you could shard your user table by region, putting all European users on one database server and North American users on another. Each shard is smaller, faster, and can be managed completely independently.
A critical mistake I see people make is waiting until their database is on fire to implement these patterns. Get a replication strategy in place early. It’s far easier to add read replicas to a well-architected system than it is to untangle a performance nightmare during a full-blown crisis.
The Critical Role Of Caching
Your database is built for persistence, but for raw speed, nothing beats a smart caching layer. Caching is the art of stashing frequently accessed data in a much faster, in-memory storage system like Redis. Instead of hammering the database for the same information over and over, your application grabs it from the cache first.
Think about a product details page on an e-commerce site. It might get viewed thousands of times an hour. By caching that product data for just a few minutes, you can serve nearly all those requests straight from memory. The database load drops to a tiny fraction of what it would have been, making your app faster and shielding your database from traffic spikes.
Navigating Data Consistency In Distributed Systems
The moment you start spreading data across multiple nodes, replicas, and caches, you run into a new challenge: consistency. How do you make sure every part of your system is working with the same, up-to-date information?
You’ll generally choose between two primary models:
- Strong Consistency: This model guarantees that any read operation will always return the absolute most recently written data. It's non-negotiable for things like financial transactions or inventory management, where seeing stale data is a complete deal-breaker. The trade-off? It often comes with higher latency.
- Eventual Consistency: This approach guarantees that, assuming no new updates are made, all replicas will eventually converge on the same value. It's a perfect fit for less critical data, like social media feeds or user comments, where a slight delay is an acceptable price for better performance and availability.
Choosing the right consistency model for each part of your application is a crucial architectural decision.
Finally, a truly scalable data strategy goes beyond just performance. It also means building reliable data pipelines to shuttle information between systems for analytics and business intelligence. To dig deeper into that topic, check out our guide on applying data pipelines to business intelligence. From bulletproof backup strategies to battle-tested recovery plans, every piece works together to create a resilient system that can grow with confidence.
Connecting Performance To An Unforgettable User Experience
Let's be honest. You can build a backend that handles millions of requests a second—a true technical marvel—but it means absolutely nothing if your user experience is slow, clunky, and frustrating. When you’re building applications meant to scale, the real finish line isn't just backend stability. It's about delivering a front-end experience that feels instantaneous.
This is where the rubber meets the road. It’s the critical link between your powerful infrastructure and what a person actually sees and feels on their screen.
Performance isn't some "nice-to-have" feature; it's a core business metric. The data from the last few years paints a crystal-clear picture of how tightly scalability, speed, and revenue are connected. Study after study confirms that a staggering 53% of users will abandon a site that takes more than three seconds to load, especially on mobile. Dig a little deeper, and you’ll find that every one-second delay in page load time can slash conversions by 7%. That penalty gets worse with every tick of the clock. This is precisely why tools like CDNs have become fundamental, not just optional add-ons. You can find more insights in these 2026 web development analyses.
Front-End Optimization For Lightning-Fast Loads
To deliver that snappy, responsive feel, you have to be strategic about what you send to the user's browser and when. It’s all about making that initial page load feel as fast as humanly possible.
Here are a few techniques that make a world of difference:
- Code Splitting: Instead of shipping one giant JavaScript file, you break it into smaller, logical chunks. The browser only grabs the code needed for the initial view, fetching other pieces as the user navigates the app.
- Lazy Loading: This is a game-changer. It defers loading non-critical assets—like images or videos that are "below the fold"—until the user actually scrolls to them. The impact on initial render time is massive.
- Modern Image Formats: It’s time to move past JPEG and PNG for most use cases. Next-gen formats like WebP or AVIF can dramatically reduce file sizes, often with no noticeable loss in quality. Smaller images mean faster downloads, simple as that.
Leveraging Caching And CDNs For A Global Audience
No matter how optimized your front-end code is, physics is still a factor. The physical distance between your server and your user creates latency. This is where a Content Delivery Network (CDN) and smart browser caching become completely non-negotiable for any serious application.
A CDN is a network of servers distributed globally. It caches your static content—images, CSS, JavaScript—in locations close to your users. When someone in London visits your site, the content is served from a nearby London server, not all the way from your primary server in New York. This simple change makes a huge difference in load times.
You can have the most scalable backend in the world, but if your assets are making a cross-continental trip for every user, your application will feel slow. A CDN is one of the highest-impact, lowest-effort investments you can make in user experience.
Beyond pure speed, a great user experience also means meeting people where they are. This includes adapting to new interaction patterns like optimizing for voice search, which improves both discoverability and accessibility for your application.
Ultimately, a fast application is a successful one. These are practical, actionable tips that directly impact your bottom line through better conversion rates and user retention. They prove that performance is the final, crucial link in the scalability chain.
Modernize And Scale With AI Management Tools
Integrating AI is the next frontier for scalable web applications. We're moving beyond just handling traffic; this is about building intelligent, responsive, and truly personal user experiences that can adapt on the fly. But as you start weaving AI into your app, you’re also introducing a whole new layer of complexity that can quickly turn into a major scaling bottleneck.
Think about it. You have to manage prompts, juggle different AI models, keep an eye on spiraling costs, and make sure everything performs consistently. It's not a trivial task. Just hardcoding prompts directly into your application is a recipe for disaster. I've seen it happen—a single, poorly worded prompt breaks a key feature, and fixing it requires a full code deployment. That slows everything down and introduces unnecessary risk.
This is exactly where a dedicated administrative tool becomes essential. Instead of treating AI as a scattered mess of API calls, a centralized management system gives you the control and visibility you need to scale your AI features with confidence.
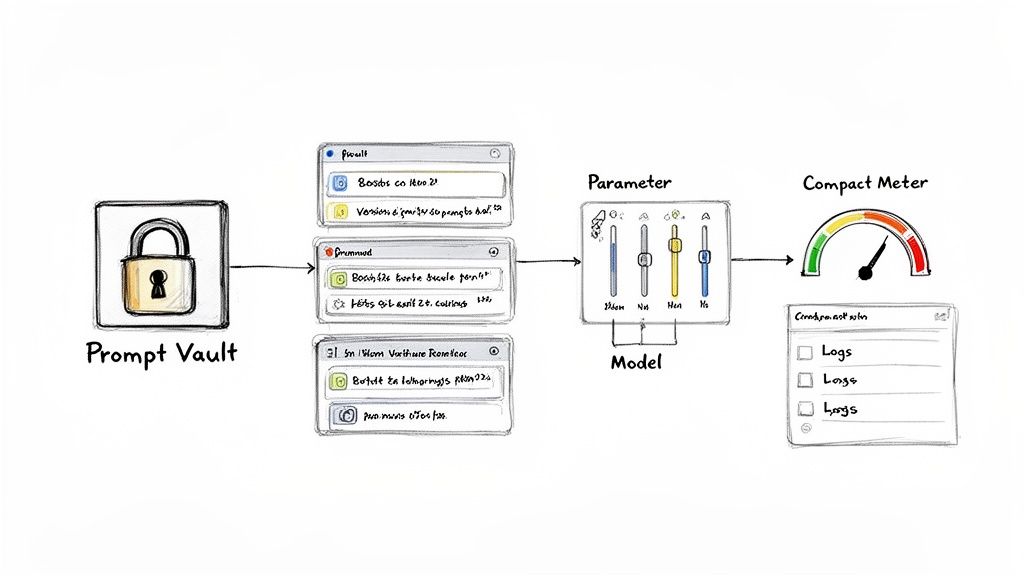
A Central Control Panel For Your AI Features
Imagine a prompt management system—like the one we've built at Wonderment Apps—as the central nervous system for your app's intelligence. It completely decouples your AI logic from your core application code. This gives you one single place to manage every single aspect of your AI integration, turning what could be a brittle, complex system into a scalable, manageable asset.
The goal is to make iterating on your AI features as easy and safe as updating content in a CMS. You shouldn't need a full development cycle just to test a new prompt or adjust a model parameter. This agility is what allows you to truly modernize and build an application that lasts.
Our administrative tool is designed to solve the biggest challenges of scaling AI. It’s something developers and entrepreneurs can plug into their existing app to modernize it for AI. The system delivers on a few critical components:
- Prompt Vault with Versioning: This is your safe space to store, test, and deploy all your AI prompts. With version control, you can experiment freely without the fear of breaking what already works. If an update causes an issue, you can roll back in an instant.
- Parameter Manager: This component securely connects your AI models to your internal databases and other data sources. It allows prompts to be dynamically populated with real-time, relevant information, which is key to delivering more accurate and personalized AI responses.
- Centralized Logging System: You need full observability into how every integrated AI model is performing. Our logging system lets you track response times, pinpoint failures, and analyze outputs across all AIs so you can continuously refine your features.
- Cost Management Dashboard: This one is crucial. You absolutely need real-time visibility into your token consumption and cumulative spend across all your models. This dashboard prevents nasty surprise bills and helps you make data-driven decisions about which AI features are actually delivering value, letting you scale your initiatives sustainably.
By centralizing all of this, you empower your team to innovate faster while maintaining the rock-solid stability that’s essential for building scalable web applications. It’s the toolkit you need to move from just experimenting with AI to deploying intelligent features that can handle enterprise-level demand.
For a closer look at how these pieces fit together, you can request a demo of our tool.
Questions We Hear All The Time
When you start digging into building scalable web applications, questions are a good sign. It means you’re thinking about the right problems. Here are some of the most common ones we hear from founders and engineering teams, along with some straight-shooting answers.
What’s the Single Biggest Mistake Companies Make?
Without a doubt, it’s premature optimization. It’s the classic over-engineering trap.
Teams get so captivated by the idea of building a system for millions of users that they architect a monstrosity before they’ve even landed their first thousand. This always leads to the same place: painfully slow development, sky-high costs, and a brittle, complex system that no single person on the team truly understands.
Instead, start with a clean, well-organized architecture that can be scaled later. This could be a thoughtfully structured monolith or just a few core microservices. Pour your energy into solid development practices, clean API design, and keeping your services stateless. This foundation gives you the flexibility to scale the specific parts of your application that actually hit a bottleneck, rather than guessing upfront and wasting a fortune on a complex system you don’t even need yet.
How Do I Know When It's Actually Time to Move to Microservices?
Let's be clear: the move from a monolith to microservices should be driven by genuine pain, not by trends. Chasing the latest architectural fad is an incredibly expensive hobby.
You'll know it's time when you start seeing these signals:
- Development Slowdown: Your teams are constantly tripping over each other. Merging code has become a high-anxiety, multi-hour ritual.
- Deployment Roulette: A tiny bug fix requires redeploying the entire application, turning every minor update into a high-stakes event.
- One-Size-Fits-None Scaling: Different parts of your app have wildly different needs. Your user authentication service, for example, might have steady, predictable traffic, while a new data processing feature gets hammered with huge, unpredictable spikes.
When these problems are actively costing you time, money, and developer sanity, that's your cue. Start by strategically carving off the most problematic or critical pieces into their own dedicated microservices.
How Can I Keep My Cloud Bill from Exploding?
Cost control isn't an afterthought; it's a core part of a scalable system. The first thing you absolutely must do is get robust monitoring and alerts in place. You can't optimize what you can't see.
A "set it and forget it" mindset with cloud infrastructure is a recipe for a budget disaster. Active management and building a culture of cost-awareness are just as crucial as your architectural choices.
Use autoscaling aggressively to match your resources to real-time demand. Why pay for servers to sit idle at 3 AM? For event-driven tasks and unpredictable workloads, lean on serverless functions—you only pay for the milliseconds of execution time.
For your steady, predictable workloads, lock in discounts with reserved instances or savings plans. And finally, give your developers visibility. When they can see the cost impact of their code in real-time, they can help you find and fix the most expensive operations.
At Wonderment Apps, we don’t just build software; we build high-performance applications designed to grow right alongside your business. If you’re ready to modernize your platform and create a truly scalable solution that lasts, we should talk.