
Microservices aren't just a buzzword; they're the architectural backbone of scalable, resilient, and future-proof applications. But transitioning from a monolith to a distributed system introduces new complexities in communication, data management, and operational oversight. Getting it right from the start is crucial for avoiding a distributed monolith, where you have all the complexity of microservices with none of the benefits.
This guide cuts through the noise to deliver a prioritized roundup of battle-tested microservices architecture best practices. We'll move beyond theory and provide actionable insights into everything from service design and data handling to observability and deployment. Each practice is a building block, and understanding how they fit together requires familiarity with core concepts. To effectively implement these strategies, a deep understanding of microservices architecture design patterns is essential for creating a cohesive and maintainable system.
As you build this robust foundation, a key challenge emerges: modernizing these services with AI. Managing prompts, models, and costs across a distributed system can quickly become an operational nightmare without the right tools. At Wonderment Apps, we've developed a specialized prompt management system—an administrative tool that developers and entrepreneurs can plug into their existing software to modernize it for AI integration. It centralizes your prompt library with versioning, manages parameters for secure data access, and provides a cost-management dashboard, freeing your developers to innovate instead of administrate.
Let's dive into the practices that create a solid foundation, and later, we'll revisit how to supercharge them with intelligent, manageable AI.
1. Single Responsibility Principle (SRP) per Service
The cornerstone of effective microservices architecture best practices is the Single Responsibility Principle (SRP). Coined by Robert C. Martin ("Uncle Bob"), this principle dictates that each microservice should have one, and only one, reason to change. This means every service is built around a specific, well-defined business capability, ensuring it remains focused, cohesive, and independently deployable.
When a service owns a single responsibility, like "User Authentication" or "Order Processing," development teams can build, test, and release updates without causing a ripple effect across the entire system. This autonomy accelerates delivery cycles and simplifies maintenance, as troubleshooting is confined to a smaller, more understandable codebase.
How to Implement SRP Correctly
Adhering to SRP prevents the creation of monolithic "god services" that are difficult to manage. A practical approach involves using Domain-Driven Design (DDD) to identify distinct business domains and their corresponding "bounded contexts." Each bounded context logically maps to a single microservice.
- Example: A fintech application might separate its services into "Customer Accounts," "Transaction Processing," and "Fraud Detection." The Transaction Processing service is solely responsible for handling payment logic; it doesn't manage user profiles or security alerts. This clear separation is key.
Actionable Tips for Applying SRP
To master SRP in your microservices, follow these guidelines:
- Define Clear Boundaries: Use DDD to map out your business domains before writing any code. This strategic planning prevents services from overlapping in function.
- Avoid Excessive Granularity: Be cautious of creating services that are too small. An "Add to Cart" service and a "Remove from Cart" service are likely too granular and should be combined into a single "Shopping Cart Management" service to avoid creating a chatty, complex network.
- Document Everything: Clearly document the responsibility, API contracts, and dependencies of each service. This documentation is invaluable for onboarding new developers and maintaining system clarity.
By embracing SRP, organizations like Netflix and Amazon have empowered small, autonomous "two-pizza teams" to own their services end-to-end, fostering innovation and unprecedented scalability.
2. API Gateway Pattern
As a microservices ecosystem grows, clients like mobile apps or web frontends face the challenge of interacting with dozens of individual services. The API Gateway Pattern solves this by acting as a single, unified entry point for all client requests. It decouples clients from the internal service architecture, simplifying client-side logic and providing a centralized point for managing cross-cutting concerns.
This pattern is a critical component of modern microservices architecture best practices, as it abstracts away the underlying complexity. Instead of a client needing to know the address and API of every single service, it makes one call to the gateway. The gateway then intelligently routes requests, aggregates data from multiple services, and translates protocols, presenting a cohesive API to the outside world.
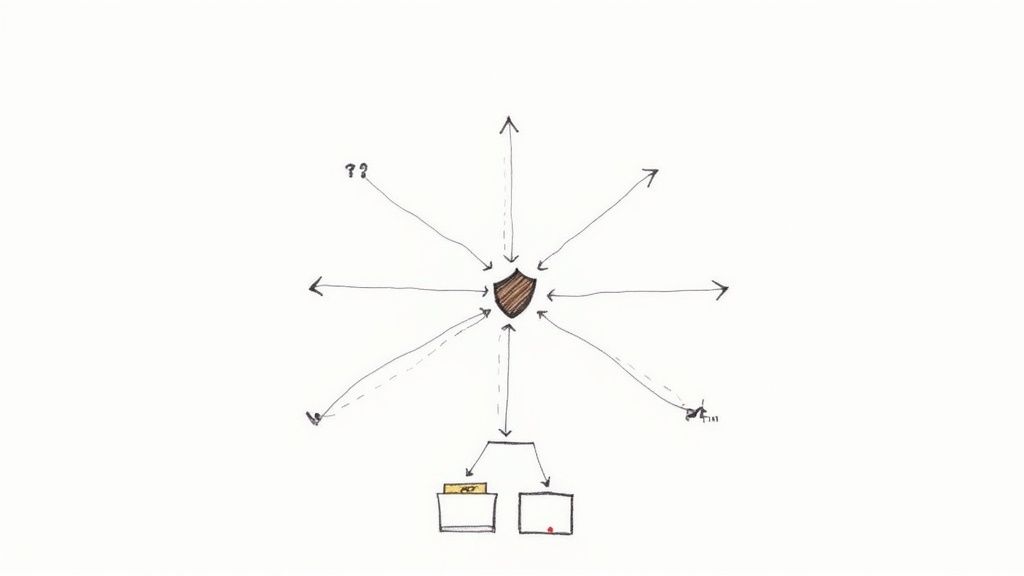
How to Implement the API Gateway Pattern Correctly
A well-implemented API Gateway does more than just route traffic. It handles crucial responsibilities like authentication, SSL termination, rate limiting, and caching. This offloads these tasks from individual services, allowing them to focus purely on their business logic. Modernizing your application with AI often involves managing complex API interactions, and a gateway can streamline this process significantly.
- Example: A retail e-commerce platform uses an API Gateway like AWS API Gateway or Kong. When a user views a product page, the mobile app sends a single request to
api.yourstore.com/products/123. The gateway authenticates the request, then fetches data from the "Product Catalog Service," "Inventory Service," and "Reviews Service." It aggregates the responses into a single payload before returning it to the app, reducing chattiness and improving performance.
Actionable Tips for Applying the API Gateway Pattern
To effectively leverage an API Gateway in your architecture, follow these guidelines:
- Design for High Availability: Never let the gateway become a single point of failure. Deploy multiple instances behind a load balancer to ensure resilience and handle traffic spikes.
- Implement Caching: Reduce latency and backend load by caching frequently requested, non-dynamic data at the gateway level.
- Monitor Gateway Performance: Track key metrics like request latency, error rates, and throughput. This provides invaluable insight into both gateway health and the performance of downstream services.
- Secure the Entry Point: Implement robust security measures like authentication (OAuth 2.0, JWT), authorization, and DDoS protection directly at the gateway. Learn more about how to design and develop excellent app experiences, including secure API management strategies.
Companies like Netflix (with Zuul) and Amazon (with AWS API Gateway) have demonstrated that this pattern is essential for managing large-scale microservices and delivering a seamless experience to end-users.
3. Database Per Service Pattern
A critical enabler of true service autonomy in microservices architecture best practices is the Database Per Service pattern. This approach dictates that each microservice must manage its own private database, which is inaccessible to other services. By decoupling data stores, teams prevent the creation of a centralized, monolithic database that becomes a bottleneck for development and deployment.
When each service owns its data, it gains the freedom to evolve independently. Development teams can modify their service's schema, scale its data tier, and even choose the best database technology for their specific needs without coordinating with every other team. This pattern, championed by pioneers like Amazon and Netflix, is fundamental to achieving loose coupling and independent scalability.
How to Implement Database Per Service Correctly
Implementing this pattern ensures that data boundaries are as clear as service boundaries. A service interacts with another service's data exclusively through its public API, never by directly accessing its database. This enforces encapsulation and prevents hidden dependencies that can cripple a distributed system.
- Example: In a retail application, the "Inventory Management" service might use a high-throughput NoSQL database like DynamoDB to track stock levels, while the "Customer Orders" service uses a relational database like PostgreSQL for its transactional integrity. The Orders service queries the Inventory service's API to check stock; it never reads directly from the Inventory database.
Actionable Tips for Applying This Pattern
To successfully implement the Database Per Service model, consider these guidelines:
- Use the Saga Pattern for Transactions: Since ACID transactions across multiple databases are not feasible, use the Saga pattern to manage data consistency across services in a distributed transaction. This involves a sequence of local transactions that can be compensated if one fails.
- Implement Event Sourcing: Capture all changes to an application state as a sequence of events. This not only provides a robust audit trail but also facilitates data replication and integration between services via an event bus.
- Plan for Data Aggregation: Since data is decentralized, create dedicated read replicas or a data warehouse for business intelligence and reporting needs. This avoids running complex, performance-draining queries against transactional production databases. You can learn more about managing databases for custom applications to optimize this process.
By giving each service its own database, organizations like Spotify empower their teams to build resilient, scalable, and maintainable systems fit for modern enterprise demands.
4. Service Discovery Pattern
In a dynamic microservices architecture, services are ephemeral; they scale up, down, or get replaced constantly. Hardcoding network locations is therefore not just impractical but a direct path to system failure. This is where the Service Discovery Pattern becomes one of the most critical microservices architecture best practices, enabling services to find and communicate with each other without static configurations.
Service discovery acts as a dynamic phone book for your services. When a service instance starts, it registers its location with a central "service registry." When another service needs to communicate with it, it queries this registry to get the most current network address. This decouples services, enhances resilience by routing around failed instances, and simplifies load balancing in complex, cloud-native environments.
How to Implement Service Discovery Correctly
Effective service discovery can be implemented through client-side or server-side patterns. A powerful approach is using a dedicated service registry tool that automates the entire process. Tools like Consul or Netflix Eureka provide robust registries, while platform-level solutions like Kubernetes offer built-in DNS-based discovery.
- Example: In an e-commerce platform deployed on Kubernetes, the "Product Catalog" service needs to fetch inventory data from the "Inventory Management" service. Instead of using a fixed IP address, it simply makes a request to a stable internal DNS name like
inventory-service.prod.svc.cluster.local. Kubernetes automatically resolves this name to a healthy, available instance of the Inventory service, seamlessly handling failover and scaling.
Actionable Tips for Applying Service Discovery
To properly implement a resilient service discovery system, consider these key actions:
- Use Health Checks: The service registry must actively monitor the health of registered instances. Services that fail health checks should be promptly removed to prevent traffic from being sent to unresponsive endpoints.
- Implement Client-Side Caching: To reduce latency and minimize traffic to the service registry, client services should cache the discovered network locations. Use a reasonable Time-to-Live (TTL) to ensure the cache is refreshed periodically.
- Plan for Registry Failure: The service registry itself is a critical component. Ensure it is highly available and resilient. Test failure scenarios, such as the registry becoming temporarily unavailable, to confirm your services can handle it gracefully.
5. Circuit Breaker Pattern
In a distributed system, network failures and service unavailability are inevitable. The Circuit Breaker pattern is an essential part of microservices architecture best practices, acting as a critical safeguard against cascading failures. Inspired by electrical circuit breakers, this pattern monitors calls to remote services and, if failures reach a certain threshold, "trips" the circuit to stop further requests, preventing a struggling service from being overwhelmed.
Instead of endlessly retrying a failing request and consuming valuable resources, the circuit breaker instantly rejects the call and returns a fallback response. After a configured timeout, it enters a "half-open" state, allowing a limited number of test requests. If these succeed, the circuit closes and normal operation resumes. If they fail, it remains open, continuing to protect the system.
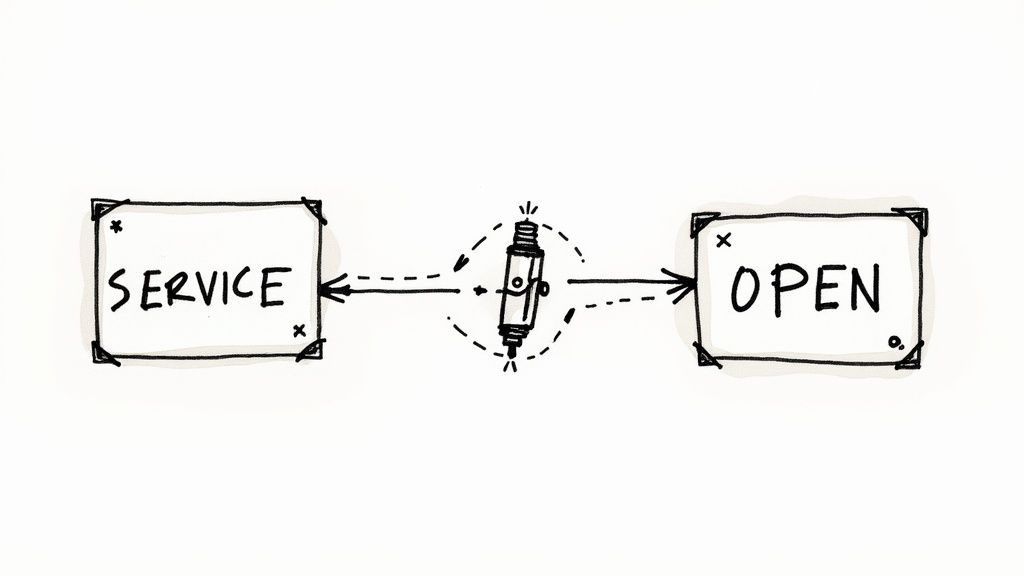
How to Implement the Circuit Breaker Pattern Correctly
Implementing this pattern builds resilience directly into your application logic. It stops a single service's downtime from bringing down the entire ecosystem. Modern frameworks and service meshes have made this pattern highly accessible, abstracting away much of the complexity.
- Example: A retail platform's "Product Recommendation" service calls an "Inventory" service. If the Inventory service becomes slow or unresponsive, the circuit breaker trips. Instead of making the user wait and eventually see an error, it immediately returns a fallback, such as a list of generic best-selling products, ensuring a graceful degradation of service. Leading libraries like Resilience4j (Java) and Polly (.NET) provide robust implementations.
Actionable Tips for Applying the Circuit Breaker Pattern
To effectively integrate circuit breakers into your microservices, follow these guidelines:
- Implement Comprehensive Fallback Strategies: A circuit breaker is only as good as its fallback. Define meaningful alternatives, such as returning cached data, default values, or simplified responses, to ensure a good user experience even during failures.
- Monitor Circuit Breaker State Changes: Actively monitor the state of your circuit breakers (closed, open, half-open). Alerts on state changes provide early warnings of system instability, allowing proactive intervention.
- Combine with Bulkhead and Timeout Patterns: Use the bulkhead pattern to isolate resources (like thread pools) for each service dependency, preventing one failing service from consuming all resources. Always combine circuit breakers with aggressive timeouts to fail fast.
By adopting the Circuit Breaker pattern, pioneered by experts like Michael T. Nygard, you can build a self-healing system that remains available and responsive even when individual components fail.
6. Centralized Logging and Distributed Tracing
In a distributed system, a single user request can trigger a chain of calls across dozens of microservices. Trying to debug an issue by manually sifting through log files on individual servers is nearly impossible. This is why centralized logging and distributed tracing are indispensable microservices architecture best practices, providing the observability needed to understand system behavior and rapidly diagnose failures.
Centralized logging aggregates log data from every service into a single, searchable location, while distributed tracing follows a request's journey across service boundaries. Together, they create a complete picture of how services interact, highlighting performance bottlenecks and error sources that would otherwise remain hidden. This unified visibility is critical for maintaining system health and reliability at scale.
How to Implement Centralized Observability
Effective observability is built on a foundation of correlation and structured data. Every incoming request is assigned a unique correlation ID (or trace ID) that is passed along in the header of every subsequent internal API call. This ID links all related logs and traces, allowing you to reconstruct the entire request flow with a single query.
- Example: A popular implementation is the ELK Stack (Elasticsearch, Logstash, Kibana) for logging, combined with an OpenTelemetry-compatible tool like Jaeger or Zipkin for tracing. When a user's payment fails, a developer can search the correlation ID in Kibana to see all logs from the Order, Payment, and Notification services, while Jaeger provides a visual timeline of the entire transaction.
Actionable Tips for Applying This Practice
To build a robust observability framework, follow these guidelines:
- Implement Structured Logging: Log messages in a consistent JSON format instead of plain text. This makes them machine-readable and easy to parse, filter, and analyze in tools like Splunk or Datadog.
- Use a Correlation ID: Ensure a unique correlation ID is generated at the system's entry point (e.g., API gateway) and propagated through every downstream service call.
- Leverage Trace Sampling: For high-traffic systems, tracing every single request can be expensive. Implement intelligent sampling to capture a representative subset of transactions without overwhelming your observability platform.
- Create Dashboards and Alerts: Proactively monitor system health by building dashboards for key metrics (e.g., error rates, latency percentiles) and setting up automated alerts for unusual patterns or critical failures.
Pioneered by companies like Google and Uber, this practice transforms debugging from a forensic nightmare into a streamlined, data-driven process.
7. Containerization and Orchestration
A cornerstone of modern microservices architecture best practices is packaging services as lightweight, portable containers and using orchestration platforms to manage them. Containerization, popularized by Docker, bundles an application's code with all its dependencies into a single executable package. This ensures the service runs consistently across any environment, from a developer's laptop to a production server. Orchestration platforms, with Kubernetes as the industry standard, then automate the deployment, scaling, and management of these containerized applications.
This combination solves the classic "it works on my machine" problem and provides a powerful framework for managing complex, distributed systems. By abstracting away the underlying infrastructure, teams can focus on building business logic while the orchestrator handles operational heavy lifting like load balancing, service discovery, and self-healing. This standardization is critical for achieving the agility and resilience promised by microservices.
How to Implement Containerization and Orchestration Correctly
Effective implementation begins with creating optimized container images and defining clear deployment manifests. Orchestration platforms like Kubernetes use declarative configuration files (typically YAML) to define the desired state of the application. The orchestrator's control plane then works continuously to ensure the actual state matches the desired state, automatically scaling pods or restarting failed containers.
- Example: An e-commerce platform can define a "Product Catalog" service in a Kubernetes Deployment manifest, specifying it needs three replicas for high availability. If one container crashes, Kubernetes automatically launches a new one to replace it without manual intervention. This declarative approach simplifies infrastructure management and enhances system reliability.
Actionable Tips for Applying This Practice
To leverage containers and orchestration effectively, apply these strategies:
- Use Multi-Stage Docker Builds: Create lean, production-ready images by separating the build environment from the runtime environment. This reduces the image size and attack surface.
- Implement Health Checks: Configure liveness and readiness probes in your orchestration manifests. These tell the orchestrator if your service is running correctly and ready to accept traffic, enabling automated recovery.
- Define Resource Limits: Set explicit CPU and memory requests and limits for each container. This prevents a single rogue service from consuming all cluster resources and impacting system stability. You can learn more about how this practice fits into a broader strategy by exploring topics in cloud computing.
By adopting containerization and orchestration, organizations empower their teams to deploy and scale services with unprecedented speed and confidence, a key enabler for successful microservices adoption.
8. Event-Driven Architecture and Asynchronous Communication
Shifting from synchronous request-response patterns to an event-driven model is a transformative step in mastering microservices architecture best practices. In this paradigm, services communicate asynchronously by producing and consuming events. When a service’s state changes, like a customer placing an order, it publishes an event to a message broker. Other interested services subscribe to these events and react accordingly, decoupling senders from receivers and eliminating direct dependencies.
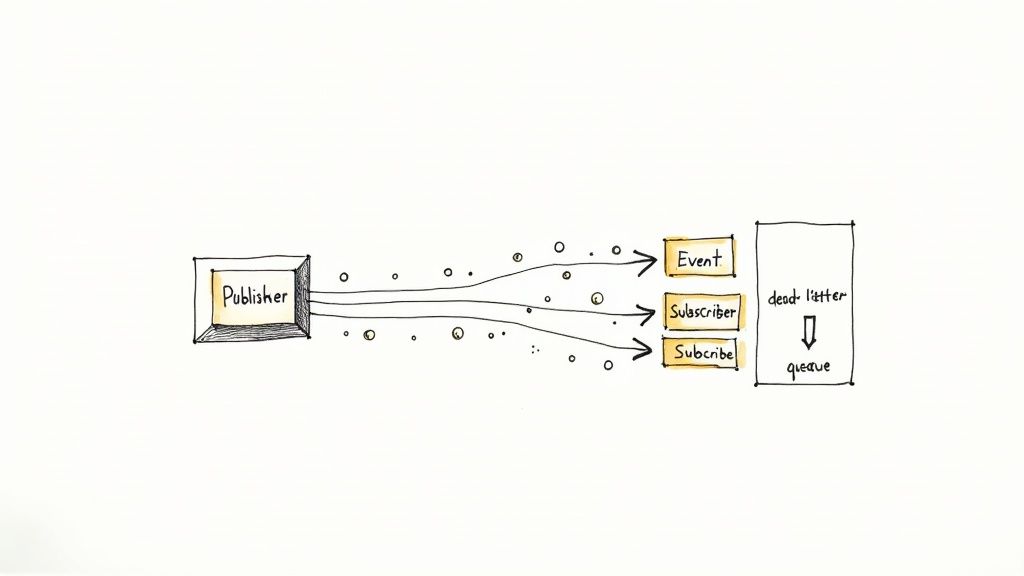
This approach dramatically improves system resilience and scalability. If a consuming service is temporarily unavailable, events can be queued and processed once it comes back online, preventing data loss and system-wide failures. This loose coupling allows teams to evolve, deploy, and scale services independently without disrupting the entire application ecosystem.
How to Implement Asynchronous Communication Correctly
The core of an event-driven architecture is a reliable message broker or event streaming platform. Technologies like Apache Kafka, RabbitMQ, or cloud-native solutions such as AWS SQS/SNS and Google Cloud Pub/Sub act as the central nervous system for inter-service communication. Services publish events to specific "topics" or "exchanges," and subscribers listen to these channels for relevant information.
- Example: In an e-commerce platform, an "Order Service" publishes an
OrderCreatedevent. The "Inventory Service" subscribes to this event to decrement stock, the "Notifications Service" subscribes to send a confirmation email, and the "Shipping Service" subscribes to prepare the shipment, all working in parallel and asynchronously.
Actionable Tips for Applying Event-Driven Architecture
To successfully implement an event-driven system, focus on reliability and maintainability:
- Design for Idempotency: Ensure that processing the same event multiple times produces the same result. This prevents duplicate data or actions if an event is redelivered due to network issues.
- Use Dead-Letter Queues (DLQs): Implement a DLQ to capture and isolate events that consistently fail to be processed. This allows you to analyze and manually resolve issues without blocking the main event queue.
- Implement Event Versioning: As your services evolve, so will your event schemas. Use a versioning strategy (e.g., adding a version field to the event payload) to ensure backward compatibility and prevent breaking changes for consumer services.
- Trace and Correlate Events: Assign a unique correlation ID to each event as it enters the system. This allows you to trace an event's journey across multiple services, which is crucial for debugging and observability in a distributed environment.
9. Configuration Management and Externalizing Configuration
One of the most crucial microservices architecture best practices for achieving true environmental independence is externalizing configuration. This practice involves separating an application's configuration from its code, allowing a single build artifact to be deployed across multiple environments (development, staging, production) without modification. Hardcoding settings like database URLs or API keys directly into the source code creates brittle, insecure, and difficult-to-manage services.
By treating configuration as an external dependency, teams can dynamically inject environment-specific values at runtime. This approach, heavily influenced by the Twelve-Factor App methodology, simplifies deployments, enhances security by isolating secrets, and enables dynamic updates without a full redeployment. It is fundamental to building a robust, scalable, and operationally sound microservices ecosystem.
How to Implement Externalized Configuration Correctly
The goal is to store configuration in a location accessible to the service during startup or runtime. This can be achieved using environment variables, dedicated configuration servers, or platform-native solutions. A centralized configuration server provides a single source of truth, version control, and access control for all service settings.
- Example: A fintech application needs different payment gateway credentials for its testing and production environments. Instead of having these keys in the code, the "Payment Processing" service fetches them from a secure external source like HashiCorp Vault. The service only needs to know the address of the Vault instance, which can be passed via an environment variable, keeping the sensitive credentials entirely separate from the deployable artifact.
Actionable Tips for Configuration Management
To effectively manage externalized configurations in your microservices, follow these guidelines:
- Separate Config from Secrets: Use distinct tools for application settings and sensitive secrets. Store general configuration in tools like Spring Cloud Config or Kubernetes ConfigMaps, while secrets should be managed in a dedicated vault like HashiCorp Vault or AWS Secrets Manager.
- Leverage Environment Variables: For containerized deployments using Docker or Kubernetes, environment variables are a simple and effective way to inject configuration, especially for bootstrap settings like the location of a config server.
- Version Your Configurations: Just like code, configuration changes should be version-controlled. This allows for easy rollbacks and provides an auditable history of changes, preventing unexpected behavior in production.
- Implement Automated Secrets Rotation: For enhanced security, automate the process of rotating sensitive credentials like database passwords and API keys. This minimizes the window of opportunity should a secret be compromised.
10. Testing Strategy: Contract Testing and Integration Testing
In a monolithic application, testing is straightforward because all components exist in a single process. Microservices architecture best practices, however, demand a more sophisticated approach. Since services are independently deployed and communicate over a network, you need a robust strategy to ensure they integrate correctly without the fragility of end-to-end tests. This is where a layered testing strategy, combining contract and integration testing, becomes essential.
Contract testing verifies that two services can communicate by checking that each service adheres to a shared "contract." It focuses on the messages and data structures passed between a service consumer and provider, ensuring that changes on one side do not break the other. This validates interactions in isolation, providing fast feedback without needing a fully deployed environment.
How to Implement a Layered Testing Strategy
The key is to verify inter-service communication without the overhead of testing the entire system at once. Consumer-Driven Contract Testing is a powerful technique where the consumer defines the expected interactions, which are then used to verify the provider's implementation. Frameworks like Pact or Spring Cloud Contract automate this process.
- Example: An "Order Service" (consumer) expects the "Payment Service" (provider) to accept a POST request with specific JSON fields. The consumer's test generates a contract file. The provider then uses this contract in its own CI pipeline to verify it meets the consumer's expectations. If the provider changes its API in a way that breaks the contract, its build fails, preventing a breaking change from reaching production.
Actionable Tips for Effective Microservice Testing
To build confidence in your distributed system, adopt these testing practices:
- Implement Consumer-Driven Contracts Early: Introduce tools like Pact at the beginning of development to establish a culture of clear API agreements between teams. This prevents integration issues from surfacing late in the delivery cycle.
- Use Test Containers for Integration Tests: For testing a service with its real dependencies like databases or message queues, use tools like TestContainers. This spins up ephemeral Docker containers for dependencies, creating an isolated and reliable testing environment.
- Mock Dependencies Strategically: Use tools like WireMock to simulate the behavior of external services during component tests. This allows you to test your service's logic, including failure scenarios like network timeouts or error responses, in a controlled manner.
By combining these methods, you build a resilient testing pyramid that catches bugs early and ensures your services work together harmoniously. For specific guidance on ensuring the quality of your distributed services, explore these essential testing strategies for microservices architecture.
10-Point Microservices Best Practices Comparison
| Item | Implementation complexity | Resource requirements | Expected outcomes | Ideal use cases | Key advantages |
|---|---|---|---|---|---|
| Single Responsibility Principle (SRP) per Service | Medium — requires domain analysis and clear boundaries | Moderate — more repos, CI/CD pipelines, governance | Focused, maintainable services; independent deploys | Large domains, team-per-capability, frequent releases | Clear ownership, faster development, simpler testing |
| API Gateway Pattern | Medium — configuration, scaling and routing logic | Moderate to high — HA gateway, caching, monitoring | Simplified client surface; centralized cross-cutting concerns | Public APIs, mobile clients, protocol translation, aggregation | Centralized auth, versioning, request aggregation |
| Database Per Service Pattern | High — distributed data management and transactions | High — multiple DBs, backup, storage, DB expertise | Loose coupling, polyglot persistence, independent scaling | Services with distinct data models or scaling needs | Data encapsulation, optimized storage per service |
| Service Discovery Pattern | Medium — registry, health checks, integration | Moderate — discovery service, monitoring, network overhead | Dynamic routing, auto-scaling support, automatic failover | Containerized/cloud environments with dynamic instances | Eliminates hardcoded addresses; supports dynamic scaling |
| Circuit Breaker Pattern | Medium — implementation and tuning of thresholds | Low to moderate — libraries, metrics, fallback services | Prevents cascading failures; graceful degradation | Unreliable downstream services, high-latency networks | Improves resilience, reduces load on failing services |
| Centralized Logging and Distributed Tracing | High — instrumentation, storage, correlation | High — log storage, tracing backend, APM tools | End-to-end visibility; faster root-cause analysis | Production troubleshooting, performance tuning, compliance | Complete observability, efficient debugging |
| Containerization and Orchestration | High initially — container design, orchestration setup | High — cluster resources, registries, monitoring, CI/CD | Consistent deployments, automated scaling, self-healing | Microservices at scale, multi-environment CI/CD pipelines | Portability, automated scaling, deployment standardization |
| Event-Driven Architecture and Asynchronous Communication | High — event design, ordering, idempotency, eventual consistency | High — message brokers, streaming infrastructure, monitoring | Loose temporal coupling, improved scalability and responsiveness | High-throughput systems, async workflows, integration flows | Decoupling, scalable async processing, resilience |
| Configuration Management and Externalizing Configuration | Low to medium — external config and secrets setup | Low to moderate — config store, secrets manager, RBAC | Environment parity; dynamic configuration updates; secure secrets | Multi-environment deployments, containers, secret-heavy apps | Safer configs, reuse of artifacts, dynamic updates without redeploy |
| Testing Strategy: Contract & Integration Testing | Medium to high — test design, orchestration, maintenance | Moderate — test frameworks, CI pipelines, mock services | Early detection of integration issues; faster feedback | Teams with many services and evolving APIs | Reduces flaky E2E tests, improves integration confidence |
Modernize and Scale Your Architecture with Wonderment Apps
Adopting a microservices architecture is a transformative journey, not just a technical switch. As we've explored, moving from a monolithic structure to a distributed system of independent services requires a fundamental shift in how we design, develop, deploy, and manage software. Mastering the ten best practices detailed in this guide, from embracing the Single Responsibility Principle and the Database Per Service pattern to implementing robust observability with centralized logging and distributed tracing, lays a critical foundation for building resilient, scalable, and maintainable applications.
These principles are not just isolated suggestions; they form a cohesive strategy. An API Gateway simplifies client interaction, while Service Discovery and the Circuit Breaker pattern ensure your distributed system remains robust and fault-tolerant. Containerization with orchestration tools like Kubernetes provides the operational backbone, and an event-driven architecture facilitates the asynchronous communication necessary for true decoupling and high performance. These are the cornerstones of successful microservices architecture best practices.
From Best Practices to Future-Proof Innovation
Successfully implementing these practices moves your organization from a state of managing technical debt to one of enabling business agility. You gain the power to innovate on individual services without risking system-wide instability, scale components independently to meet demand, and empower smaller, autonomous teams to deliver value faster. This architectural freedom is the ultimate goal: creating a system that can evolve with your business needs and technological advancements, not one that holds them back.
However, in today's landscape, building a scalable architecture is only half the battle. The next wave of modernization involves integrating artificial intelligence to deliver smarter, more personalized user experiences. This introduces a new layer of complexity, particularly within a distributed microservices environment. How do you manage and version thousands of AI prompts across dozens of services? How do you securely pass parameters to your models, track performance, and control the exploding costs of token usage? These are the new challenges that can derail even the most well-architected systems.
The Next Frontier: Managing AI in a Microservices World
This is precisely where the vision for Wonderment Apps was born. We recognized that while microservices solve the problem of application scalability, AI integration introduces a new, complex management problem. Our prompt management system is engineered to solve it, acting as a central nervous system for your application's intelligence layer.
Imagine a world where your development teams don't have to worry about the operational overhead of AI. Our platform provides:
- A Centralized Prompt Vault: Manage, version, and deploy prompts for all your AI models from a single source of truth, ensuring consistency and control across every microservice.
- A Secure Parameter Manager: Safely connect your internal database access to your AI models without exposing sensitive information, maintaining compliance and security.
- Comprehensive Logging: Gain deep visibility into every AI interaction across your distributed system with our logging system across all integrated AIs.
- A Unified Cost Manager: Track your cumulative spend across all integrated AI models in real-time, preventing surprise bills and enabling better financial governance.
By abstracting this immense complexity, we empower your teams to focus on what they do best: innovating and building intelligent features that delight your users. You’ve already committed to modernizing your architecture with microservices; now it's time to equip it for the age of AI.
Ready to bridge the gap between a modern architecture and an intelligent application? See how the Wonderment Apps platform can streamline your AI integration, control costs, and accelerate your journey from best practices to breakthrough innovation. Request a demo today and let our expert developers help you build a truly future-proof application that is built to last.