
Building scalable, intelligent software today is not just about writing code; it's about choosing the right architectural blueprint. Moving from a monolithic structure to a microservices architecture is the key to unlocking unparalleled scalability, resilience, and the ability to integrate cutting-edge AI. Get it right, and you build an application that can adapt and grow for years. Get it wrong, and you are left with a distributed monolith that's more complex and costly than what you started with.
This guide breaks down the essential, real-world example microservices architecture patterns that successful companies use to build applications that serve millions. We will dive deep into not just what they are, but precisely how and when to use them, providing replicable strategies you can apply directly to your projects. We'll explore critical patterns like the API Gateway, Database Per Service, and event-driven models, giving you a tactical playbook for building robust, modern systems.
As you explore these patterns, consider how modernizing your app also means preparing it for advanced AI integration. A critical piece of that puzzle is managing how your new services interact with AI models, a task that can quickly become a major headache. At Wonderment Apps, we developed a prompt management system that acts as an administrative tool developers and entrepreneurs can plug into their app to modernize it for AI. This tool provides the backbone for making AI integration seamless and scalable from day one, which we'll touch on more later. For now, let’s explore the architectures that will power your success.
1. API Gateway Pattern with Service Mesh
Combining an API Gateway with a Service Mesh creates a robust, secure, and observable example microservices architecture perfect for complex, high-stakes environments. This pattern establishes a clear separation of concerns: the API Gateway acts as the single, managed entry point for all external client requests, while the service mesh handles the intricate and often chaotic communication between internal microservices.
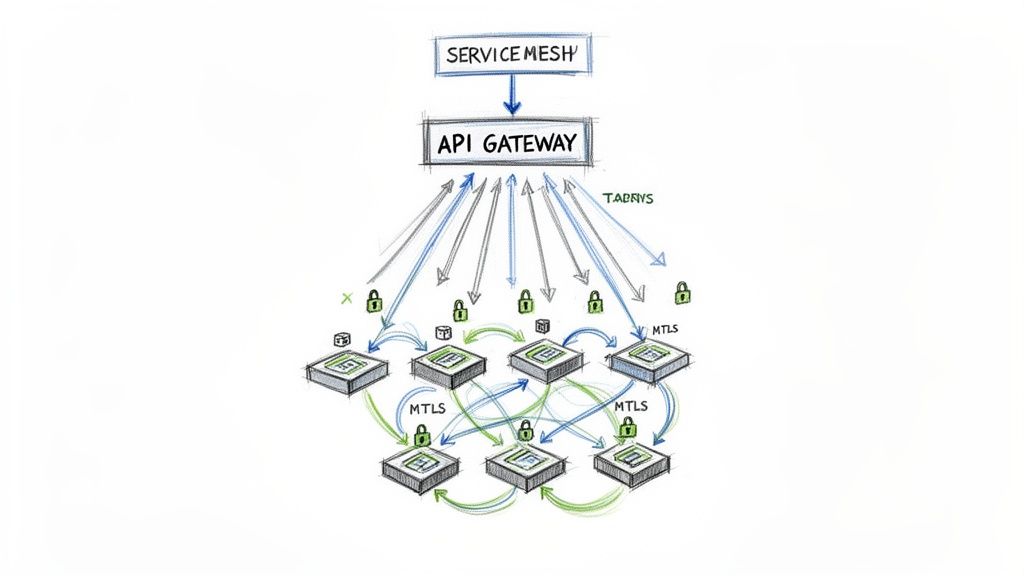
The API Gateway (like AWS API Gateway or Kong) is responsible for "north-south" traffic, managing tasks like authentication, rate limiting, and request routing. The service mesh (like Istio or Linkerd) manages "east-west" traffic, providing service discovery, load balancing, and mutual TLS (mTLS) encryption for secure inter-service communication. This dual-layer approach simplifies individual service logic by offloading complex networking and security tasks to the infrastructure layer.
Strategic Breakdown and Implementation Tips
This architecture shines in regulated industries like fintech and healthcare, where strict access control and detailed audit trails are non-negotiable. For instance, Netflix famously uses a custom API Gateway to handle billions of daily requests, while Uber leverages a service mesh built on Envoy to manage its vast network of services.
Actionable Takeaways:
- Phased Rollout: Start by implementing the API Gateway first. This simplifies the initial setup and provides immediate value by centralizing external access control. Introduce a service mesh later as inter-service communication complexity grows.
- Gateway-Level Logging: Implement comprehensive, structured logging at the gateway. This creates a centralized, immutable audit log of every external request, which is critical for meeting compliance standards like HIPAA or PCI DSS.
- End-to-End Visibility: Use distributed tracing tools (e.g., Jaeger, Zipkin) integrated with your service mesh. This allows you to follow a single request from the moment it hits the gateway through its entire journey across multiple microservices, drastically reducing debugging time.
- API Design Choices: The gateway is where your API contract is exposed. Deciding on the right API style is critical for performance and developer experience. Exploring the nuances of GraphQL vs REST can help you determine whether a flexible query language or a standardized, stateless approach is better for your specific use case.
Key Insight: The primary benefit of this pattern is decoupling. Your front-door security (API Gateway) is decoupled from your internal network security (Service Mesh), and both are decoupled from the business logic within your microservices. This separation allows specialized teams to manage each layer independently, accelerating development and improving security posture.
2. Database Per Service Pattern
The Database Per Service pattern is a foundational example microservices architecture that dictates each microservice must manage its own, private database. This model ensures true autonomy and loose coupling by preventing services from directly accessing each other's data stores. Instead of a single, monolithic database shared by all, each service owns its data, promoting independent development, deployment, and scaling.
This architecture fundamentally changes how data consistency is managed. Traditional distributed transactions (like two-phase commits) are replaced with patterns like event sourcing and the Saga pattern, which rely on eventual consistency. Communication between services to share or update data happens asynchronously through an event bus or messaging queue, creating a more resilient and scalable system.
Strategic Breakdown and Implementation Tips
This pattern is a game-changer for organizations aiming for high agility and scalability. For example, Shopify leverages this architecture to scale its commerce platform, allowing the product catalog service's database to scale independently from the order processing service's database. Similarly, Amazon’s vast e-commerce backend relies on this decentralized data model to manage millions of concurrent operations across different service domains.
Actionable Takeaways:
- Embrace Event-Driven Communication: Implement a robust event bus (e.g., Kafka, RabbitMQ) to handle communication and data synchronization between services. This is the backbone of maintaining consistency in a decentralized data environment.
- Implement the Saga Pattern: For complex business transactions spanning multiple services, use the Saga pattern to manage a sequence of local transactions. Each step publishes an event, triggering the next, with compensating transactions to roll back changes if a step fails.
- Choose the Right Tool for the Job: A key benefit is polyglot persistence. Your user authentication service might use a relational database for its structured data, while a product recommendation service could use a graph database for its complex relationships. Understanding the differences when comparing options like Oracle vs. PostgreSQL becomes critical for optimizing each service's performance.
- Establish Clear Data Ownership: Meticulously document data ownership boundaries within your domain model. This clarity prevents ambiguity, reduces inter-team dependencies, and ensures that only the owning service can write to its database, enforcing the pattern's core principle.
Key Insight: The primary benefit is team and service autonomy. By decoupling the database, you decouple the teams. Each team can independently select their database technology, manage their schema, and scale their data tier without coordinating with or impacting other teams, dramatically increasing development velocity.
3. Event-Driven Architecture (Event Streaming)
An event-driven architecture is a highly decoupled and scalable example microservices architecture where services communicate asynchronously. Instead of making direct requests to each other, services publish "events" (records of business state changes) to a central event streaming platform. Other services subscribe to these streams, reacting only to the events relevant to their function. This pattern fosters resilience and autonomy among services.
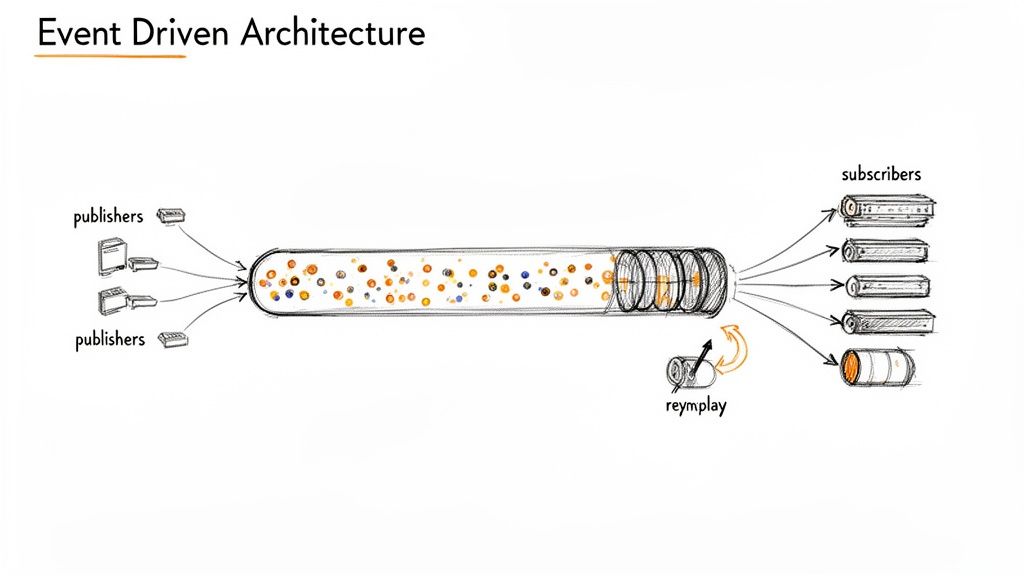
This model uses a message broker or event stream processor like Apache Kafka, AWS Kinesis, or RabbitMQ as the system's backbone. When an Order Service creates an order, it publishes an OrderCreated event. The Inventory Service and Notification Service subscribe to this event to independently update stock levels and send a confirmation email, respectively. The Order Service doesn't need to know its consumers exist, enabling true loose coupling.
Strategic Breakdown and Implementation Tips
This architecture is the lifeblood of real-time, high-volume systems. For example, Uber's entire ride-matching and pricing engine relies on streaming millions of events per second. Similarly, financial institutions use event streams for instant fraud detection and transaction processing, where every event creates an immutable audit trail. Shopify also leverages this to manage its complex order, inventory, and fulfillment pipeline.
Actionable Takeaways:
- Choose the Right Broker: Use a powerful platform like Apache Kafka for high-throughput, persistent, and mission-critical event streams. For simpler message queuing and task distribution, RabbitMQ is often a more straightforward choice.
- Establish a Schema Registry: Implement a schema registry (e.g., Confluent Schema Registry) from day one. This enforces a contract for event structures, preventing downstream services from breaking when an upstream service changes its event payload.
- Design Domain-Centric Events: Model your events around business concepts (
UserRegistered,PaymentProcessed) rather than technical actions (UserRowInserted). This makes the system more understandable, adaptable, and aligned with business goals. - Handle Failures Gracefully: Implement dead-letter queues (DLQs) to capture and isolate "poisoned" messages that repeatedly fail processing. This prevents a single bad event from halting an entire consumer and allows for later analysis and reprocessing.
Key Insight: The core strength of this pattern is temporal decoupling. Producer services can publish events even if consumer services are down or slow. Consumers can process events at their own pace and can even replay the event stream to rebuild their state, providing immense operational flexibility and fault tolerance.
4. Strangler Fig Pattern (Legacy System Modernization)
The Strangler Fig Pattern offers a pragmatic and low-risk approach to migrating from a legacy monolith to a modern example microservices architecture. Instead of a high-stakes "big bang" rewrite, this strategy gradually replaces pieces of the monolith with new microservices. A routing layer, often a reverse proxy, is placed in front of the legacy system to intercept requests, directing traffic to either the new microservice or the old monolith, depending on which functionality has been migrated.
This pattern is named after the strangler fig plant, which grows around a host tree and eventually replaces it. Similarly, the new microservices architecture gradually envelops and eventually supplants the legacy system, allowing for incremental modernization while the original system remains operational. This minimizes disruption and allows teams to deliver value continuously throughout a long-term migration project.
Strategic Breakdown and Implementation Tips
This architecture is the go-to solution for established enterprises in retail, finance, and logistics that cannot afford the downtime or risk of a complete system overhaul. For example, Target successfully modernized its core retail platform using this method, maintaining 24/7 operations. Major European banks have also used it to incrementally replace aging core banking systems that are decades old.
Actionable Takeaways:
- Identify High-Value, Low-Risk Modules: Begin by identifying and extracting functionality that is both valuable to the business and relatively isolated. This "first slice" provides a quick win and helps the team build momentum and experience with the process.
- Use a Feature Flag System: Implement a robust feature flagging tool (like LaunchDarkly or Unleash) to control the traffic routing at the proxy layer. This allows you to perform canary releases, directing a small percentage of users to the new service first and rolling back instantly if issues arise.
- Maintain Data Consistency: Plan for a data synchronization strategy between the old and new systems. Techniques like event-driven data replication or dual-writing can ensure both systems have a consistent view of the data during the extended transition period.
- Modernize Incrementally: This pattern is a cornerstone of a successful upgrade. You can learn more about how to modernize legacy systems with a phased, strategic approach that de-risks the entire initiative.
Key Insight: The core benefit of the Strangler Fig Pattern is risk mitigation. It transforms a monumental, high-risk rewrite into a series of manageable, low-risk steps. Each successful migration builds confidence and provides immediate business value, making the overall modernization effort more sustainable and likely to succeed.
5. Saga Pattern for Distributed Transactions
The Saga pattern provides a robust mechanism to manage data consistency across multiple microservices in a distributed environment where traditional two-phase commit transactions are not feasible. This example microservices architecture pattern orchestrates complex, multi-step business processes by breaking a global transaction into a sequence of local transactions. Each local transaction updates the database in a single service and triggers the next step, ensuring the overall process completes successfully or is properly compensated for.
Sagas are coordinated through two primary methods: Choreography and Orchestration. Choreography uses an event-driven model where services publish events that trigger actions in other services, creating a loosely-coupled system. Orchestration uses a central coordinator (an orchestrator) that directs the sequence of operations, telling each service what local transaction to execute. This centralized control simplifies complex workflows with many steps or conditional logic.
Strategic Breakdown and Implementation Tips
This pattern is indispensable for transactional systems like e-commerce, fintech, and logistics, where a single business operation (e.g., placing an order) involves multiple independent services. Amazon uses sagas for its complex order fulfillment process, and Uber relies on them to coordinate the steps of booking a ride from matching a driver to processing payment and completing the trip.
Actionable Takeaways:
- Design Compensating Transactions: For every step in the saga that modifies data, you must design a corresponding compensating transaction to undo the action. If a payment fails, a compensating transaction would cancel the shipment or release reserved inventory.
- Implement Idempotency: Services must handle duplicate messages or requests without causing unintended side effects. Use idempotency keys to ensure that a retried step (e.g., a payment charge) is processed only once, preventing issues like double billing.
- Choose the Right Coordination Model: Use choreography for simple, linear workflows where loose coupling is a priority. For more complex, branching, or long-running processes, use an orchestration engine like Temporal or Cadence to manage state and logic centrally.
- Utilize Distributed Tracing: Visualize the entire flow of a saga across multiple services using distributed tracing tools. This is crucial for debugging failures, identifying performance bottlenecks, and understanding how a business process executes in a distributed system.
Key Insight: The core strength of the Saga pattern is its ability to maintain data consistency without the tight coupling and availability risks of distributed transactions. It embraces the reality of distributed systems by prioritizing resilience and eventual consistency, allowing individual services to fail and recover without bringing the entire business process to a halt.
6. CQRS (Command Query Responsibility Segregation)
CQRS, or Command Query Responsibility Segregation, is an advanced example microservices architecture that radically optimizes performance and scalability by separating data modification from data reading. In this pattern, "Commands" (write operations like create, update, delete) are handled by one model and often a dedicated database, while "Queries" (read operations) are handled by a completely different, highly optimized read model. This split allows each side to be scaled and structured independently for its specific task.
The write model focuses on transactional integrity and business logic, often paired with Event Sourcing to maintain a complete, immutable log of all changes. The read model, by contrast, is a denormalized projection of the write data, specifically designed to answer queries as fast as possible. This separation is powerful for complex systems where the demands of writing data (e.g., processing an order) are vastly different from the demands of reading it (e.g., powering a real-time analytics dashboard).
Strategic Breakdown and Implementation Tips
This architecture is a game-changer for domains with high-throughput transactions and complex, demanding query requirements. For example, financial trading platforms use CQRS to process a high volume of orders (commands) while simultaneously serving real-time market data analytics (queries). Similarly, Booking.com leverages this pattern to manage hotel inventory (write side) while powering its sophisticated, high-performance search functionality (read side).
Actionable Takeaways:
- Targeted Implementation: Don't apply CQRS to your entire system. Start with a single, bounded context where the read and write patterns are clearly divergent and causing performance bottlenecks. This minimizes initial complexity.
- Embrace Eventual Consistency: The read model will naturally lag behind the write model. It's crucial to monitor this synchronization delay and design user interfaces that gracefully handle potentially stale data. Business stakeholders must understand and accept these trade-offs.
- Optimize Read Models for Queries: Create multiple, purpose-built read models (materialized views) from the same stream of events. You might have one read model optimized for a user dashboard, another for an admin reporting tool, and a third for a recommendation engine, all without impacting the write model.
- Plan for Rebuilds: Your read models should be entirely disposable. Implement a mechanism to rebuild them from the event store (your write model's source of truth). This is invaluable for recovering from failures, evolving schemas, or creating new query models.
Key Insight: CQRS decouples the conceptual model of your data. The write side is optimized for consistency and enforcing business rules, while the read side is optimized purely for speed and the specific needs of the consumer. This separation allows you to build systems that are both resilient to change and incredibly performant under demanding, asymmetric workloads.
7. Observability Stack (Logs, Metrics, Traces)
An observability stack is not a single pattern but a foundational capability essential for any viable example microservices architecture. It is built on three pillars: logs (discrete, timestamped events), metrics (time-series numerical data), and traces (the end-to-end journey of a request). In a distributed system, where a single user action can trigger a cascade of calls across dozens of services, this tripartite view is the only way to understand system behavior, diagnose failures, and optimize performance.
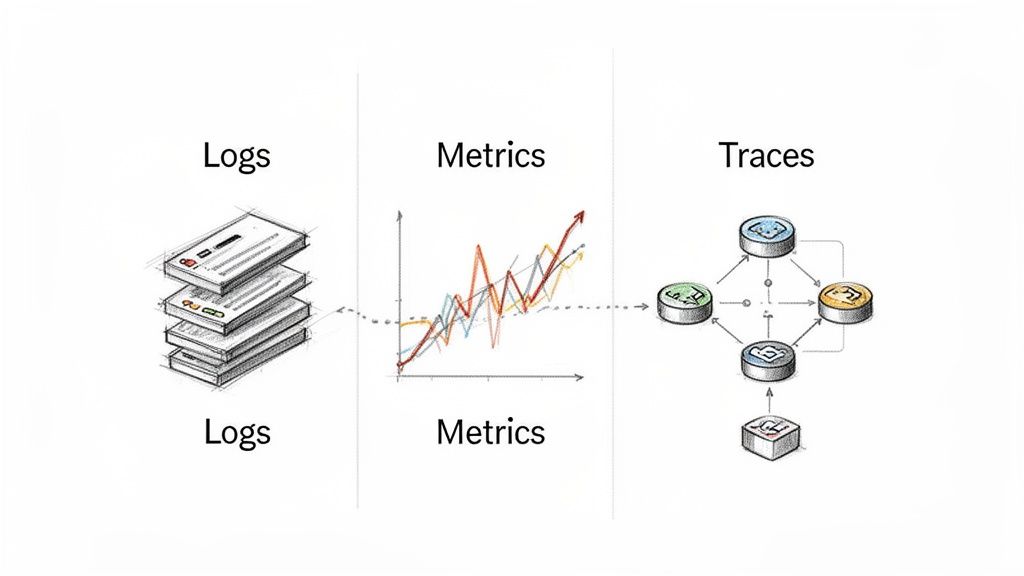
This approach centralizes diagnostics by correlating data from all three sources. For instance, a spike in a metric (like error rate) can be investigated by finding the corresponding trace to identify the failing service, and then drilling down into that service's logs to find the specific error message and context. This integrated visibility transforms troubleshooting from a needle-in-a-haystack search into a structured, data-driven process.
Strategic Breakdown and Implementation Tips
This architecture is non-negotiable for any at-scale microservices deployment. Uber famously monitors billions of metrics with its M3 system, while Netflix relies on a custom stack including Prometheus and Grafana for platform health. For fintech companies like Stripe, detailed observability is critical for tracking every financial transaction and ensuring the integrity and reliability of the payment processing pipeline.
Actionable Takeaways:
- Implement Structured Logging: Standardize your logs in a machine-readable format like JSON from day one. This makes them easy to parse, query, and index in tools like Elasticsearch, dramatically speeding up root cause analysis.
- Use Correlation IDs: Propagate a unique request ID (or trace ID) across every service call, log entry, and metric. This simple step is the key to linking the three pillars of observability together, allowing you to follow a single transaction through the entire system.
- Monitor Business and System Health: Create dashboards that display not only technical Service Level Indicators (SLIs) like latency and error rates but also business-level Key Performance Indicators (KPIs) like user sign-ups or completed orders. This connects system performance directly to business impact.
- Trace All Critical Paths: Ensure distributed tracing is implemented for all external API calls, database queries, and asynchronous message queue interactions. This provides a complete picture of request lifecycles, pinpointing bottlenecks that cross service boundaries.
Key Insight: Observability is about asking new questions about your system, not just viewing pre-defined dashboards. A mature stack allows engineering teams to dynamically query and explore system behavior in real-time. It shifts the operational mindset from reactive monitoring ("is the system up?") to proactive analysis ("why is latency 10ms slower for this user segment?").
8. Service-to-Service Authentication (mTLS and OAuth 2.0)
In a distributed system, securing communication between services is as critical as protecting the external perimeter. This example microservices architecture pattern combines Mutual TLS (mTLS) for transport-level authentication and encryption with OAuth 2.0 for application-level authorization. This layered approach creates a zero-trust environment where no service is trusted by default, and every interaction is explicitly verified and authorized.
mTLS establishes a secure, encrypted channel by requiring both the client and server services to present and validate cryptographic certificates before any communication occurs. This confirms who is making the request. Layered on top, OAuth 2.0 uses access tokens (like JWTs) to define what the requesting service is permitted to do, providing granular, delegated authorization. This dual mechanism ensures that only authenticated services can communicate, and they can only perform actions they are explicitly allowed.
Strategic Breakdown and Implementation Tips
This security model is the standard in high-compliance sectors like fintech, healthcare, and government, where strong identity verification and auditable access control are mandatory. For instance, financial institutions rely on mTLS for all internal traffic to prevent data interception, while platforms like Google Cloud and Stripe use OAuth 2.0 to manage API permissions for their vast ecosystem of services. The Kubernetes control plane also heavily utilizes mTLS to secure communication between its core components.
Actionable Takeaways:
- Transparent mTLS with a Service Mesh: Manually managing certificates for every service is a significant operational burden. Implement a service mesh like Istio or Linkerd to automate mTLS certificate issuance, rotation, and enforcement, making security transparent to developers.
- Principle of Least Privilege: Define OAuth 2.0 scopes with extreme granularity. A "billing" service should not have a token that grants access to "user profile" data. This minimizes the potential impact of a compromised service.
- Centralize Token Validation: Use a dedicated identity and access management (IAM) service or a centralized authorization service to issue and validate OAuth 2.0 tokens. This prevents each microservice from having to implement complex and potentially insecure validation logic.
- Monitor Certificate Health: Certificate expiration is a common cause of production outages. Implement automated monitoring and alerting to warn teams weeks in advance of certificate expiry, allowing for seamless, zero-downtime rotation. For securing your service-to-service communication, it's vital to explore robust authentication mechanisms and best practices.
Key Insight: This pattern separates authentication (identity verification via mTLS) from authorization (permission granting via OAuth 2.0). This separation of concerns allows security and infrastructure teams to manage the secure communication fabric, while application teams can focus on defining fine-grained access policies based on business logic, creating a more secure and scalable system.
8-Pattern Microservices Architecture Comparison
| Pattern | Implementation complexity | Resource requirements | Expected outcomes | Ideal use cases | Key advantages |
|---|---|---|---|---|---|
| API Gateway Pattern with Service Mesh | High — requires gateway + mesh expertise | High — proxies, control plane, monitoring, compute | Centralized access control, observability, traffic management; small added latency | Large microservices platforms; fintech & healthcare; high-traffic e‑commerce | Centralizes cross-cutting concerns, transparent mTLS, canary/traffic splitting |
| Database Per Service Pattern | Medium–High — domain modeling, eventual consistency design | Medium–High — multiple DB instances/schemas to operate | Independent scalability and polyglot persistence; eventual consistency tradeoffs | Teams owning bounded contexts; systems needing DB tech diversity | Service autonomy, reduced coupling, independent DB scaling |
| Event-Driven Architecture (Event Streaming) | High — event design, ordering, idempotency complexity | High — streaming platform, storage, monitoring | Loose coupling, real-time processing, event replay and audit trails | High-throughput real-time systems, analytics, fintech, inventory streaming | High throughput, replayability, easy feature extension via subscriptions |
| Strangler Fig Pattern (Legacy Modernization) | Medium — routing, synchronization, parallel ops | Medium — duplicate infra during migration, integration tooling | Incremental migration with reduced risk; longer parallel operations | Enterprises modernizing monoliths (banks, retailers, gov) | Minimize disruption, phased rollouts, validate new services with real traffic |
| Saga Pattern for Distributed Transactions | High — compensating actions, orchestration/choreography logic | Medium — coordinator or event infrastructure and monitoring | Coordinated multi-step transactions without 2PC; eventual consistency | E‑commerce order flows, payment settlements, complex business workflows | Enables multi-service transactions; supports long‑running processes and compensations |
| CQRS (Command Query Responsibility Segregation) | High — separate models, sync and rebuild complexity | High — distinct read/write stores, event stores, projection infra | Optimized reads and writes, denormalized read models, eventual consistency | Read-heavy systems, complex queries, trading platforms, analytics | Independent scaling of read/write, superior read performance, multiple projections |
| Observability Stack (Logs, Metrics, Traces) | Medium — instrumentation and alert design | High — storage, processing, dashboards, retention | Faster detection & diagnosis, capacity planning, compliance-ready audit trails | Any microservices at scale; compliance-sensitive orgs (fintech/healthcare) | Comprehensive visibility, correlated diagnostics, reduced MTTR |
| Service-to-Service Authentication (mTLS & OAuth 2.0) | Medium–High — cert rotation, IAM and token workflows | Medium — PKI, token services, policy management | Encrypted authenticated calls, fine‑grained authorization, audit logs | Fintech, healthcare, government, sensitive internal APIs | Strong mutual authentication, delegated authorization, compliance support |
Build Your Future-Proof Application with the Right Partner and Tools
Navigating the world of microservices is much like studying a collection of architectural blueprints. Throughout this article, we've dissected several powerful example microservices architecture patterns, from foundational concepts like the API Gateway and Database Per Service to advanced strategies such as the Saga Pattern for distributed transactions and the Strangler Fig for legacy modernization. Each pattern offers a distinct solution to the complex challenges of building scalable, resilient, and maintainable applications.
The core lesson is clear: there is no one-size-fits-all solution. The optimal architecture for an e-commerce platform prioritizing rapid feature deployment will differ significantly from a fintech application where transactional integrity and security are paramount. Your choice depends entirely on your specific business domain, technical constraints, and future growth objectives. Adopting these patterns isn't just about breaking down a monolith; it’s about strategically embracing modularity to gain a competitive edge.
From Blueprint to Reality: Key Strategic Takeaways
As you move from theory to implementation, remember these critical insights drawn from the examples we've explored:
- Decoupling is Your North Star: The primary goal of patterns like Event-Driven Architecture and Database Per Service is to create true independence between services. This autonomy is what enables parallel development, isolated fault tolerance, and independent scaling.
- Embrace Observability from Day One: A distributed system is inherently more complex to monitor. Implementing a comprehensive observability stack with logs, metrics, and traces isn't an afterthought; it is a fundamental requirement for debugging and maintaining system health.
- Plan for Data Consistency: Patterns like Saga and CQRS directly address the challenges of managing data across distributed services. Acknowledging that traditional ACID transactions are not feasible is the first step toward designing robust, eventually consistent systems.
- Security is a Distributed Responsibility: In a microservices environment, security shifts from a single perimeter to a multi-layered approach. Patterns like service-to-service authentication using mTLS and OAuth 2.0 are essential for establishing a zero-trust network.
Mastering these architectural concepts is the first step. The next is executing them flawlessly, which requires not only technical expertise but also the right tooling to manage the increasing complexity, especially as you integrate modern capabilities like Artificial Intelligence.
The AI-Powered Future of Microservices
As you build or modernize your application using a sophisticated example microservices architecture, integrating AI is no longer a futuristic goal but a present-day necessity. AI can power personalization engines, automate complex data analysis in a healthcare pipeline, or provide intelligent fraud detection in a fintech backend. However, this introduces a new layer of complexity: managing the prompts, models, and costs associated with these AI services.
This is precisely where specialized tooling becomes a game-changer. Imagine trying to manage dozens of evolving AI prompts across multiple microservices without version control or a centralized repository. The operational overhead would be immense, stifling innovation.
Strategic Insight: A successful microservices strategy in the AI era must include a plan for managing AI integrations as a core architectural component, not as an add-on. Centralized AI governance tools prevent chaos and ensure scalability.
Wonderment Apps has developed a powerful prompt management system designed to plug directly into your modern architecture. It acts as a centralized "mission control" for all your AI integrations, providing your development teams with the structure they need to innovate responsibly and efficiently. Our toolkit includes:
- A Prompt Vault with full versioning to track changes, experiment with new prompts, and roll back if needed.
- A Parameter Manager for securely connecting prompts to your internal databases, allowing AI to access real-time, relevant data.
- A unified Logging System to monitor all interactions and responses across every integrated AI model for debugging and auditing.
- A Cost Manager that gives entrepreneurs and business leaders clear, cumulative visibility into their AI spend.
Choosing the right architectural patterns sets the foundation. Partnering with an expert team and equipping them with the right tools ensures your vision becomes a scalable, intelligent, and future-proof reality.
Ready to translate these architectural blueprints into a powerful, AI-enhanced application? Let Wonderment Apps be your guide. We specialize in helping businesses design, build, and modernize applications using the very patterns discussed here, with a unique focus on seamless AI integration. Schedule a free demo of our AI Prompt Management Toolkit and discover how to build an intelligent architecture that scales with your ambition.